Yeah, now I understand that it’s basically unusable — after just 4 requests, it crashed, and those were just regular ones.
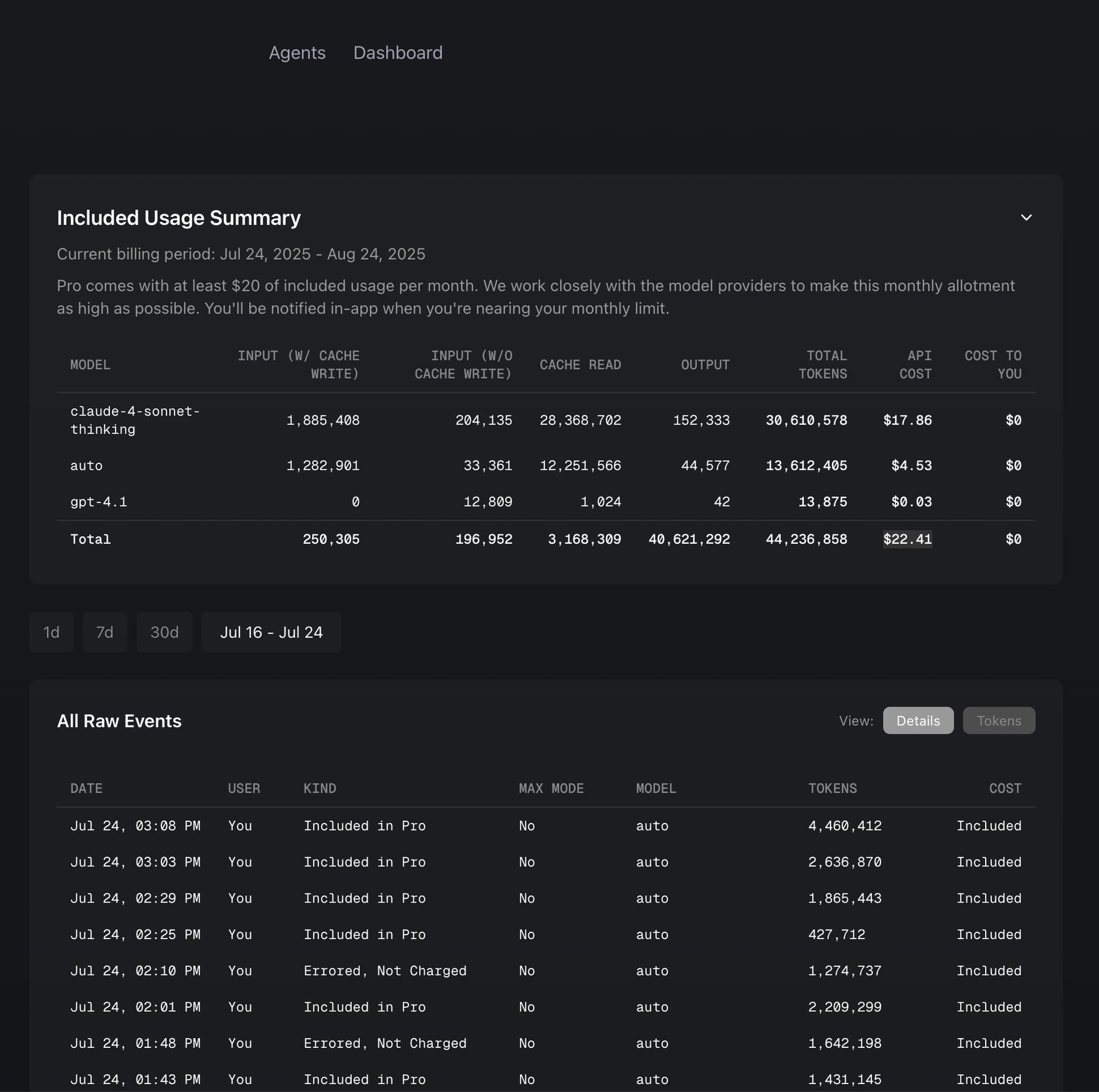
Over 7 days, I made around 100 requests, including failed ones, since the start of the subscription. Apparently, the shown usage includes previous months as well.
And while using the agent on those 4 requests, it made a bunch of incorrect changes, nullifying all the queries.
It seems like our limits are shared with other users, providers, and overall load — some people get a lot of requests, while others get just a few. It’s like playing roulette.
To be honest, I don’t even feel like paying $20 for this kind of experience
Moreover, the statistics now show token counts that have nothing to do with reality — it feels like they’ve been multiplied several times.
I don’t understand the point of displaying this, since it provides no meaningful value
You can click the Tokens button to break them down further, but good luck finding information about what each token type actually is and what each one costs
I managed to make two more requests, but they were just as useless and only messed up the code. You could say 4.1 is basically free, but o3 ended up costing $1 per request, considering the error message.
This is just insane, and now the agent doesn’t consume just 1 request like before.
What was it you said, uncle? A generous offer?"
I have exactly same problem. After 3 I spent all limits. (after upgrade to 1.2.1).
It just eat to much token in each response. o3 parses 3 small files (300-400 lines each) and took 800k tokens. This is not normal guys.
I’m making a request to the model with context from several files, with a total context size of about 50KB. The output consists of minor edits, barely reaching 1–2KB.
So where do these huge numbers like ‘Output: 12,638, Cache Read: 437,222’ come from in a regular model request, where the context is supposedly limited to 120K, and the request ends up costing around $1?
Fix your infrastructure issues and bugs — we shouldn’t have to suffer or pay for your mistakes that prevent us from working.
@wtester cache read is from using existing cached chat thread at API provider. Cache reads are the cheapest tokens as they do not need to be re-processed. However reading that many tokens from cache means a lot of detalis must be considered by AI.
There wasn’t such consumption before — the context used to come from the attached files, and the AI would think a little instead of searching through files. Now it ends up using 500k tokens, and sometimes even a few million.
This is clearly your problem, and if you don’t fix it, no one is going to pay you for a pumpkin-shaped carriage. You still have time to make things right. You’re already seeing that Cursor AI is getting worse and worse with each iteration, limiting users while hiding behind good intentions.
It’s not new for you to mess up and charge money for nothing, just like when new models were introduced before.
Right now, this is just burning money with no benefit. I used to make about 250 requests per month and that was enough — now it’s practically unusable.
@wtester I would appreciate a proper respectful communication. As a forum moderator I am here helping you and not the cause of issues. Rage comments and disrespectful inconsiderate behavior is not helping solve your issue. Im happy to discuss with you details and provide you help, with constructive communication only.
Thank you for your understanding and following Forum Guidelines.
Previously, the same type of request with a 120k context cost $0.04 — now it costs $1. What kind of improvement is that?
I don’t think anyone here is naïve — everyone keeps track of money, especially when it brings no real value.
And this isn’t just my personal criticism or dissatisfaction — it’s happening everywhere now, from Twitter to Reddit.
This is criticism aimed at Cursor AI’s policy, so that your leadership understands where things are heading.
I have no complaints against you — you’re doing your job, and I’m thankful for that.
I just want to convey that there’s no smoke without fire. My main goal is to point out the shortcomings so that you can improve.
@wtester is there a need to type in bold? Its so much harder to read.
I understand your issue and sure before we users could load a lot of context into one request while the cost was just $0.04. Now its more transparent and fair, also I would prefer to have more heavier usage included in my Pro plan.
Ok lets look at the 120k context: If you send 1 request with 120k input tokens it costs at Anthropic $0.36 not just $0.04 and this is not even counting any output tokens. which cost 5x more.
With the old plan I used up my 500 requests in 2 weeks, and paid for the rest of month with usage based pricing. Now its not really much different, I am watching my consumption and careful not to attach unnecessary tokens to avoid running into limits too early. But I am aware that I have heavier consumption than what it would cost me if I use the Anthropic API directly while still covered by the Pro plan. For more focused usage when i reach the limits I turn on usage based pricing to bridge it, not all the time.
Cursor team is aware of the feedback and they are making improvements. Docs got updated, users got a plan in between the 2 main plans as they wanted that, tokens are now shown on usage which is also what users asked for.
Changes may take time and Michael from Cursor has mentioned in his post in the forum about the plan changes, that they could have done things better.
What I personally see is when users are outraged (regardless who caused it) it just inflames other users instead of focusing on the issue and working together on improvements.
I appreciate your feeback, please have a look at the Token view in Usage Dashboard, it can show you what consumes so much. Note that Cache read is the cheapest token usage but having a lot of tokens consumed overall may signal that more optimized AI usage would save you a lot.
Im not excusing Cursor just highlighting details and suggesting improvements.
Note that Cursor team is reading posts and looking what improvements they can make.
PS this is not my job, I’m a professional developer.
Hello everyone, Cursor of course the best in the Market but. Can someone explain to me how the new price system works? It’s been less than 24 hours and it’s already $22.41. I don’t understand how this works.
So far it’s still working perfectly, but when the project is finished, I don’t know yet how much I’ll have to pay.