How to disable Cache Write and Cache Read? Claude is too expensive now. After a detailed inspection, I found that more than 80% of the cost is caused by this. How to turn off Cache Write and Cache Read?
Hi @ok1122
There is no way to disable Cache Read and Write as this is done by AI API providers internally. The reason is that cache reads are saving you cost and avoiding re-processing of data.
Cache reads are good as this means that the Chat session including any context (files, rules,..) is already cached and costs 10% of the price compared when the whole chat needs to be processed again after you submit follow-up prompts.
Without Cache Reads the cost would go up for the input by 9x approximately.
The difference to before is that now the Cache Read and Write parts are shown in detail but Chat and Agent had for a while this feature since AI providers added it.
Could you share how many tokens were Cache read or written?


Are there any higher-end packages? The $200 package is too little.
Cache write in this case means that new context (code, MCP tool response, …) was added to chat.
Cache reads are large in your case which could be a sign of very long chats or a lot of context being required by AI to create a response. I recommend focusing chats on a specific task or topic. When changing task or topic a clean chat helps keep the AI also more focused on a good response as otherwise it gets easier confused.
Here are some of my usage details. You can see on last line that a new chat was started (cache writes), and then later that cache was reused (read) by AI.

For now the Ultra plan is the largest and from there on it goes with Usage Based Pricing but I will forward your feedback to Cursor Team.
Saw you added a cool profile pic, nice ![]()
Thanks for your answer, now I understand that a chat window should focus on one specific thing. Simple questions need to be communicated in a new window.
Also for simple questions or code research use Auto, then for actual coding or task planning Sonnet.


Those assumptions are inaccurate as they do not contain all relevant information. Asking any AI with only partial information can not lead to a proper response.
A detailed breakdown is shown in following post.
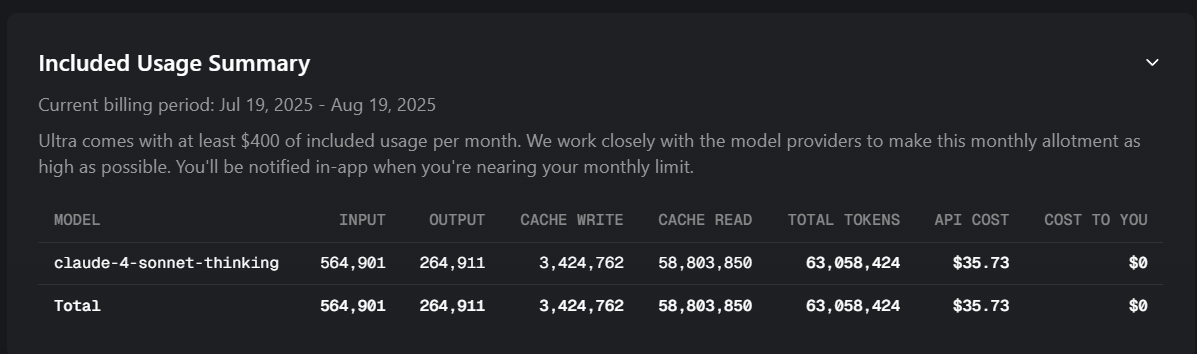
? I pasted a screen shot of my usage directly from the Cursor My Account website. 92 million read cache for only 245k input and 528 output tokens is absurd. By definition Read Cache is a method to use only 10% of tokens by having Claude remember data already used. How can something that is supposed to be 10% of the input/output tokens be 120x (12000%) more tokens/use/cost.
I didnt address the screenshot as an issue, but the interpretation caused by giving Claude incomplete information.
Read Cache is used to not have to process the data again as input tokens. The price of Cache Read tokens is 10% of Input price of tokens. Cache gets used as much as there are either tool calls or follow up requests in same thread.
The statement By definition Read Cache is a method to use only 10% of tokens by having Claude remember data already used. is inaccurate.

Here are details on Token usage. It explains cache reads well.
If you have a question on cache reads im happy to answer.
The last screenshot seems reasonable. Extremely high input token usage, just 10x the cache reads.
(note that the totals on bottom is a calculation error and is being addressed)
Regardless of the basis of cache code, they are drastically higher than any other IDE using the same claude 4 sonnet model. Can you address how cache reads with windsurf and other IDE’s are staying at their normal rates with proper cache read, same with Claude code, Cline, Roocode. People are being charged $75 for 1 million tokens used? If I use Ask mode in cursor it doesn’t create millions of tokens in cache read.
Should users be charged $75 for 1 million claude 4 sonnet tokens? Is that the policy of Cursor? $75 per 1 million input/output tokens using Sonnet (not claude)?
There is a clearly an issue with the updated prompt or something that is generating an unruly amount of cache read. I’ve seen 50+ people post about this in the past few days. I am not getting unruly cache reads from claude code, cline, roocode, windsurf using the same Claude 4 Sonnet model.
If you guys aren’t able to acknowledge and fix it. It’s ok I’m going to leave Cursor permanently after a year of using it every day and signing up for the ultra plan. I was literally charged $35 for half a days use with ultra, totaling 68 million tokens in half a day with claude 4 sonnet. When on the same exact project I’ve used pro+ for months without ever going over limit of tokens. I hit limit in 6 days, with this cache read issue, just like hundreds of other people.
I see a bloodbath of people leaving cursor, and I can’t blame them if cursor won’t even acknowledge the issue. With same usage and same webapp project that would last all month, I shouldn’t be out of tokens with same usage in 6 days, or using $35 in half a day with same models that would last all month.
The tokens are reported by AI providers based on usage and they are charged as consumed.
If someone decides to provide as input 18000+ pages (8M tokens, not 1 million) and has several tool calls, and follow up questions, then the consumption is appropriate for usage.
Details of consumption are not shown in the screenshot and therefore cant be answered as it only shows a summary. If the user finds an issue with this they should report it to [email protected] as only they have insight into it.
Im not aware what other companies tools are doing with tokens.
There is no issue with a prompt as it cant generate cache reads, AI provider manages that part.
Why are you making up a fake scenario of 8M input tokens? I gave clear examples to respond to: Look at the image below only 245,343 input tokens and 527,755 output tokens and it generated 92 million cache read tokens and charged $75.
This is not 8M tokens in, its less than 1M tokens in (across multiple prompts not a single prompt).

Why make up a fake scenario of 8M tokens in, when I gave you a real world numbers to respond to?
I addressed a clear scenario from the previous image you uploaded. Lets focus on only that example and not switch them constantly.
8,000,000 tokens / 1.3 = ~6,154,000 words
Estimated 18,000 - 23,000 book pages
The user had over 8M input tokens (minimum 18 000 book pages)
We can from cache Read see that the cache was used at least 10 times or more, not unusual for cache reads.
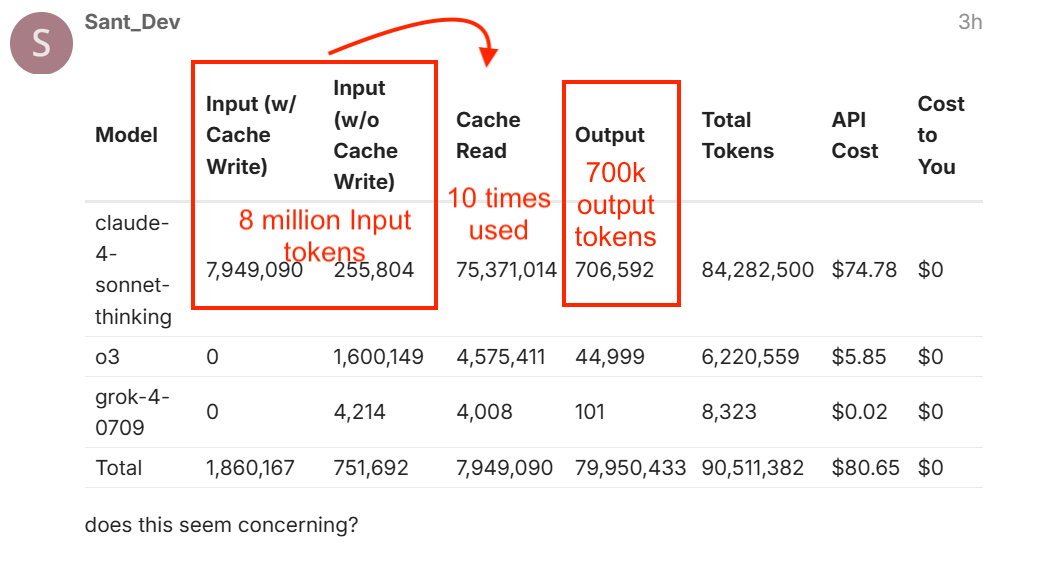
Without cache read, the cost for just input tokens have been 8M * $3.6/1M tokens * 10x usage = $288 and this is without any output tokens.
Then explain how a Pro+ account worked for 5+ months on the same exact size project without ever hitting its limit all month? Did Cursor bait and switch an initial usage calculation/charging and replace it with one 70x more expensive? I used to spend $60/month with Pro+ which would cover all the edits I needed to the same project that now charged $35 for 68 million tokens in half a day?
Explain how this is not a bait and switch please? Why did my pro+ account used to cover 600+ Sonnet requests per month, and this month less than 60 request used up all $60 on the plan? I’m not getting more than 60 requests before using all my credits now.
Please explain clearly what changed to cause this, because I’m ready to leave Cursor and scream from the mountain tops on youtube videos that everyone else should too. This is rediculous, I’m working on the same project that the Pro+ covered dev for all month, not 6 days like it does now.