Really enjoying Cursor Pro and loving how it helps with AI-powered editing.
But… something’s not adding up when it comes to token usage and I think it’s worth discussing openly here.
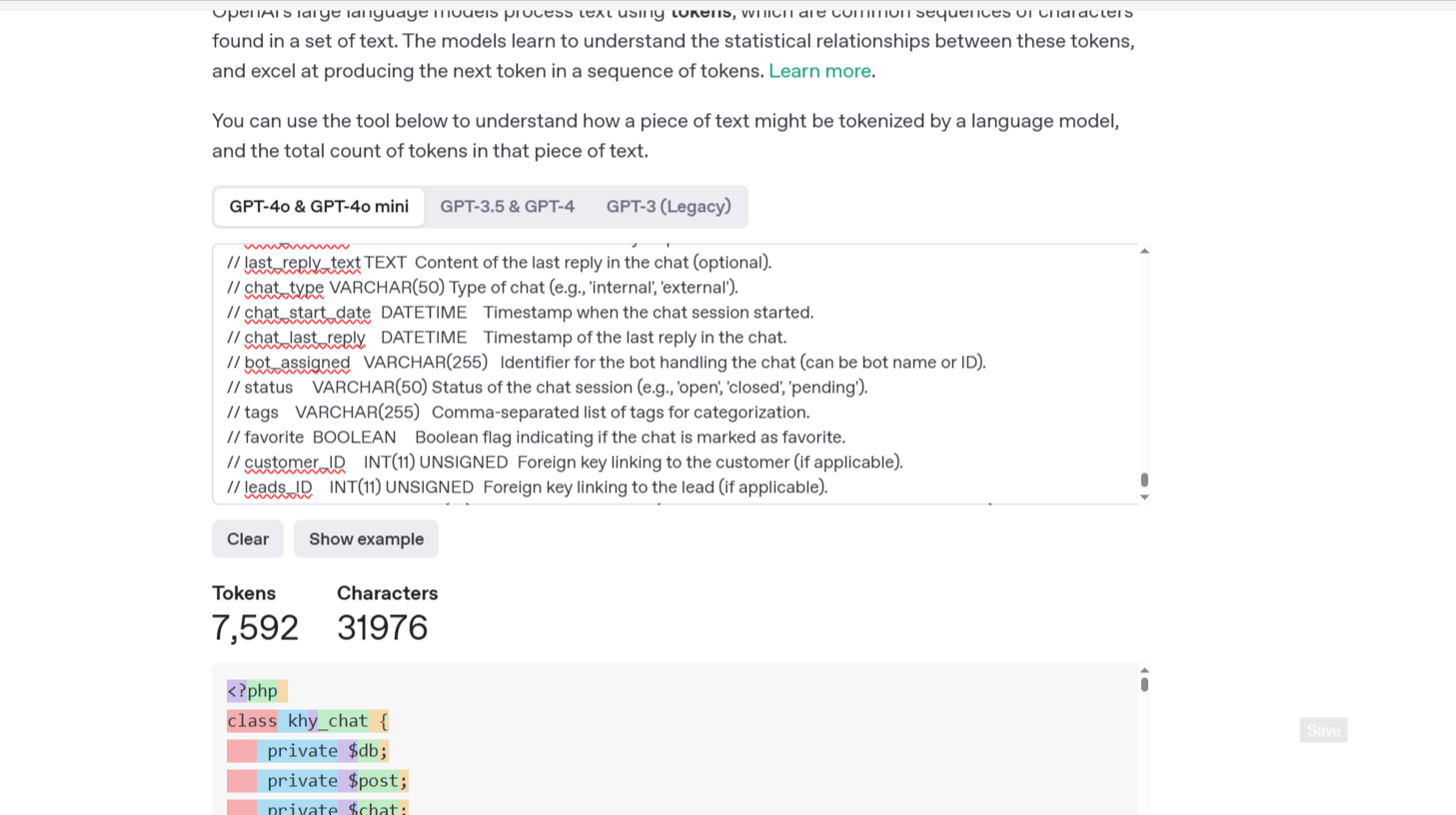
Here’s what happened: I edited a single file that was about 7,500 tokens in total size (see screenshot below). After that one edit, Cursor’s dashboard shows that I used over 107,000 tokens for that one transaction!
That’s not a typo — one simple edit, on one moderate-sized file, burned through (107k tokens in one go).
This honestly shocked me. When I was thinking about building something like this myself, I would have expected this workflow to consume that much over the (course of an entire week) — not a single edit.
And this wasn’t some crazy large context or complex prompt — just normal editing.
Even accounting for caching, summarization, etc., I can’t help but feel like (there’s a lot of invisible overhead going on here).
This matters because:
If every small edit costs this much in tokens, it could explain why people hit limits faster than expected.
Users might not realize that a “minor” edit can result in massive token charges behind the scenes.
I’d bet there’s at least 70%+ potential savings possible here without impacting quality — just with more efficient prompt design and context management.
I’d be interested to hear if others have observed similar patterns, and would appreciate any insight from the Cursor team on how this token usage is calculated for these types of edit actions.
My goal in raising this is simply to understand how the system works and whether there are future plans for further optimization.
Thanks again to the Cursor team for the great product — this just seemed like an important topic to discuss constructively.
Yes, but this was around 10x the tokens, not just a 10% variance from tokenizer differences, so I don’t think it’s a tokenizer mismatch issue.
This was a single API request using “Claude 4” (not Fast Edit), on a single file that totaled approximately 7,500 tokens.
However, Cursor’s dashboard shows that this request consumed over 107,000 tokens — suggesting that the entire file content may have been sent repeatedly within that one request.
From what I can tell, this implies there might not have been effective caching or summarization applied at the prompt layer, at least for this workflow.
It feels like the file could have been included multiple times in prompt chains or intermediate calls during processing, which adds significant hidden token overhead.
Sorry for that i mean it was single request using claude 4, not single api request,and also i selected the lines i want to edit and did not leave it to read whole file to find it, and it take 10x tokens than file size
This was less than 50 lines of code, but the output consumed 107K tokens.
Honestly, when I was planning an editor for my internal company use, I wasn’t expecting to send the entire code 10 times in a single request, that kind of behavior feels really strange.
It seems like there’s a significant opportunity here for Cursor to restructure how prompts and code are sent to expensive models like Claude Sonnet or Opus, possibly from the ground up.
If it’s helpful, happy to volunteer some time to think through this with the team
A-lot of people are having this same issue. I messaged Cursor and they said that I should switch to Auto for the time being. Like I paid $200 to not have access to the models in my plan lol. If they don’t fix this soon, ill either try to force a refund, or chargeback.
Looks very strange really, why do they use this sum of tokens even? I think they have long sequence of calls and everytime the send full code again, they can - with small manipulation - sent only the structure and avoid such big usage, lets wait for the explanation
Use auto first, because it is free, and then if it doesn’t work revert to the old version and then try a specific model. Even better, automate the process and track performance differences.
It’s a lot better than it used to be. I spent most of the day giving identical prompts to claude and auto, and auto produced working code 15 percent faster on average than claude took to produce very buggy code even when handed the problem.
They both started with empty fields and they both were given the exact same prompts.
I can beat you when it comes to tokens consumed…
Agent Claude 4 Sonnet
Input 42
Output 2,383
Cache write 63,111 Cache Read 474,254 Total Tokens 539,790
luckily was within the plan. But this makes me nervous about pricing and usage cost once I run out of the plan (and this month I almost haven’t touched Cursor)
And all that it is achieving,- is for me to look at going Claude path (since that’s pretty much only model I use and seems to work). I tried Grok 4,- froze in the middle every single time!
So it sends your code about 8 times to clause before get you the output, why? and why it sends complete code again and again, its very easy to change their prompt structure and summerize code to avoid this, I think cursor is depending 100% in selected AI when you select model manually, so it sends all your code to selected model again and again instead of passing it first to smaller model to optimize it.