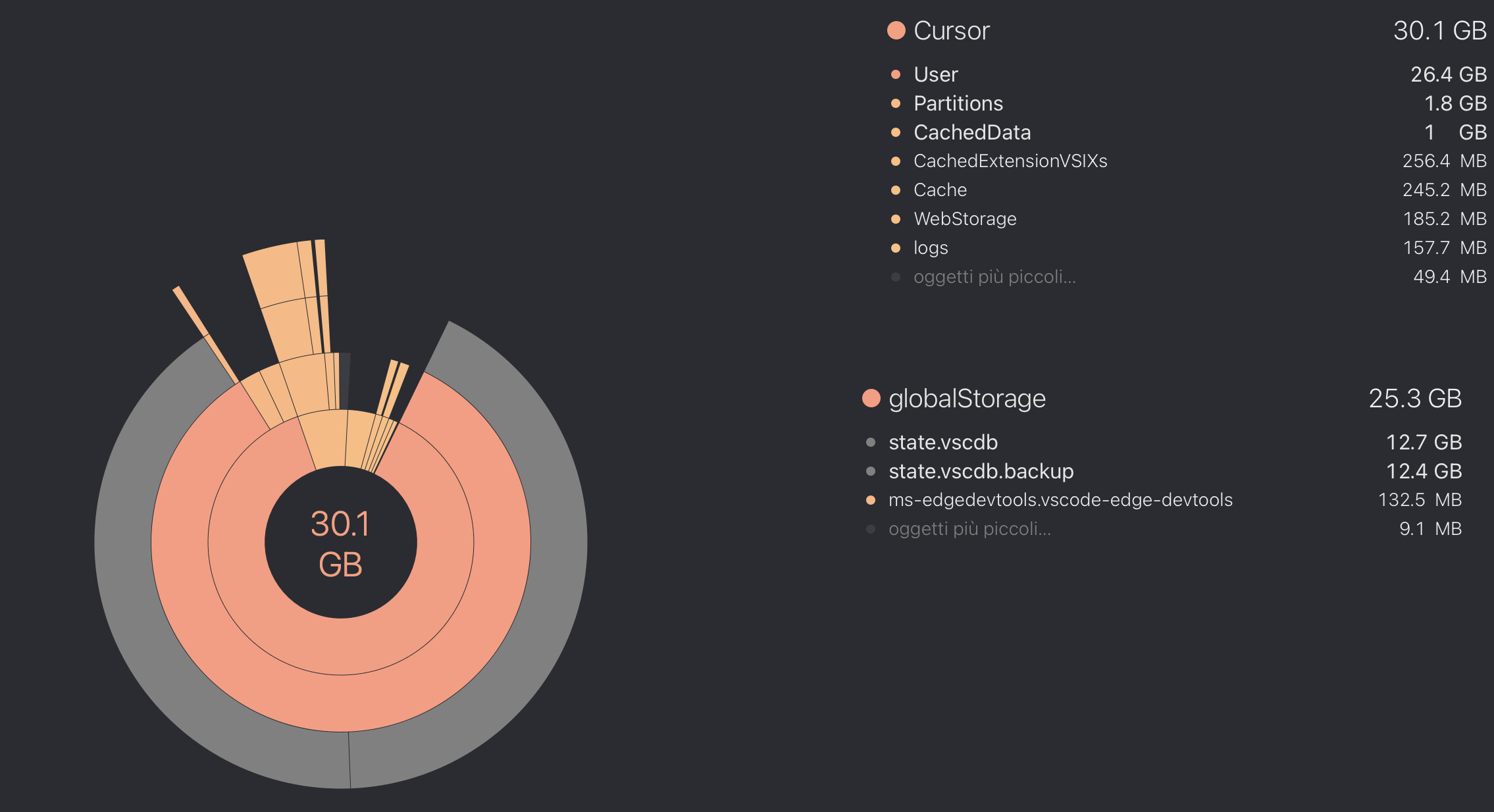
I also encountered high state.vscdb size at ~13.7GB. I havent’t definitively diagnosed cause, but I did recently start adding many cloned Git repos into my project filesystem under /repos/* weighing in at around 77GB (note, these were just git cloned, not git submodules). I didn’t have a .cursorignore for those initially and Cursor may have started indexing or doing something with those files? The symptoms leading me here was Cursor staying alive for around 10-15 minutes before crashing with error below. The crash often accompanied a CPU activity spike, but not always.
My attempt to cleanup follows, I’m monitoring for addition crashes presently (cleanup script collapsed below). This got the state.vscdb down to 23.8MB.
—-
I ran this on the global DB:
~/Library/Application Support/Cursor/User/globalStorage/state.vscdb
SELECT name, SUM(pgsize) AS size_bytes
FROM dbstatGROUP
BY nameORDER
BY size_bytes
DESCLIMIT 10;
Result:
- cursorDiskKV: 13,641,699,328 bytes
- sqlite_autoindex_cursorDiskKV_1: 99,713,024 bytes
- ItemTable: 5,296,128 bytes
- sqlite_autoindex_ItemTable_1: 225,280 bytes
Counts:
- cursorDiskKV rows: 976,000
- ItemTable rows: 2,338
Integrity check:
PRAGMA integrity_check;
=> fails with “database disk image is malformed” and index errors (sqlite_autoindex_cursorDiskKV_1).
Sampling cursorDiskKV keys (first 20k rows) shows biggest prefixes are:
bubbleId, agentKv, checkpointId, messageRequestContext, codeBlockDiff.
So in my case the bloat is real payload growth in cursorDiskKV (not just fragmentation), and the backup DB also shows corruption signals.
I ran this script below to test if DB shrinking fixes, NOTE, this backs up the existing state.vscdb store, but “Loading Chat” will occur in all chats and has a known bug as above. Though full jsonl chat transcripts are available at ~/.cursor/projects//agent-transcripts//.jsonl and not lost.
Cleanup script
# Cursor state.vscdb cleanup + compaction (macOS)
# This removes the large cursorDiskKV payload families and shrinks the DB file.
set -euo pipefail
DB="$HOME/Library/Application Support/Cursor/User/globalStorage/state.vscdb"
DIR="$HOME/Library/Application Support/Cursor/User/globalStorage"
TS="$(date +%Y%m%dT%H%M%S)"
echo "Using DB: $DB"
# 1) Stop Cursor first (important to avoid lock/partial writes)
pkill -f '/Applications/Cursor.app/Contents/MacOS/Cursor' || true
pkill -f '/Applications/Cursor.app/Contents/Frameworks/Cursor Helper' || true
sleep 1
# 2) Backup
cp "$DB" "$DIR/state.vscdb.bak-precleanup-$TS"
echo "Backup created: $DIR/state.vscdb.bak-precleanup-$TS"
# 3) Delete biggest offenders (chat/composer/checkpoint blob families) + compact
sqlite3 "$DB" <<'SQL'
PRAGMA journal_mode=DELETE;
BEGIN IMMEDIATE;
DELETE FROM cursorDiskKV WHERE key LIKE 'agentKv:%';
DELETE FROM cursorDiskKV WHERE key LIKE 'bubbleId:%';
DELETE FROM cursorDiskKV WHERE key LIKE 'checkpointId:%';
COMMIT;
VACUUM;
PRAGMA wal_checkpoint(TRUNCATE);
SQL
# 4) Verify
echo
echo "Post-cleanup counts:"
sqlite3 "$DB" "
SELECT 'agentKv', COUNT(*) FROM cursorDiskKV WHERE key LIKE 'agentKv:%'
UNION ALL
SELECT 'bubbleId', COUNT(*) FROM cursorDiskKV WHERE key LIKE 'bubbleId:%'
UNION ALL
SELECT 'checkpointId', COUNT(*) FROM cursorDiskKV WHERE key LIKE 'checkpointId:%';
"
echo
echo "File sizes:"
ls -lh "$DB" "$DIR"/state.vscdb.bak-precleanup-"$TS"
stat -f '%N %z bytes' "$DB" "$DIR"/state.vscdb.bak-precleanup-"$TS"