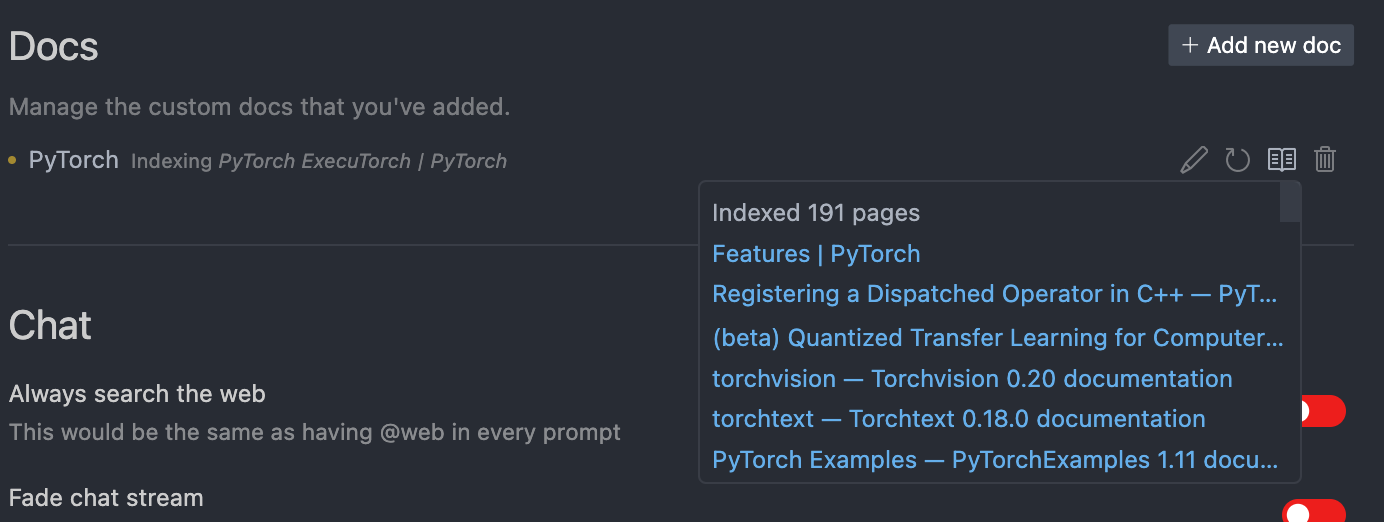
The feature of scraping docs is great — but it often doesn’t work as intended. The scraper usually doesn’t hit all the sites necessary.
Any chance we can see the full list of pages scraped? It shows a count but the list doesn’t load.
This is would be huge for me as I often use libraries that aren’t super common.