I’m still having issues with Gemini and tools. The only model able to use tools is 1.5-pro and only in manual mode. The other models just freeze up, with some even printing the underlying tool call command into the code it’s attempting to write.
I added my Gemini API yesterday and ran some tests with different models in different modes here. Have some request IDs as well but wasn’t sure if they were okay to share on forum, lmk
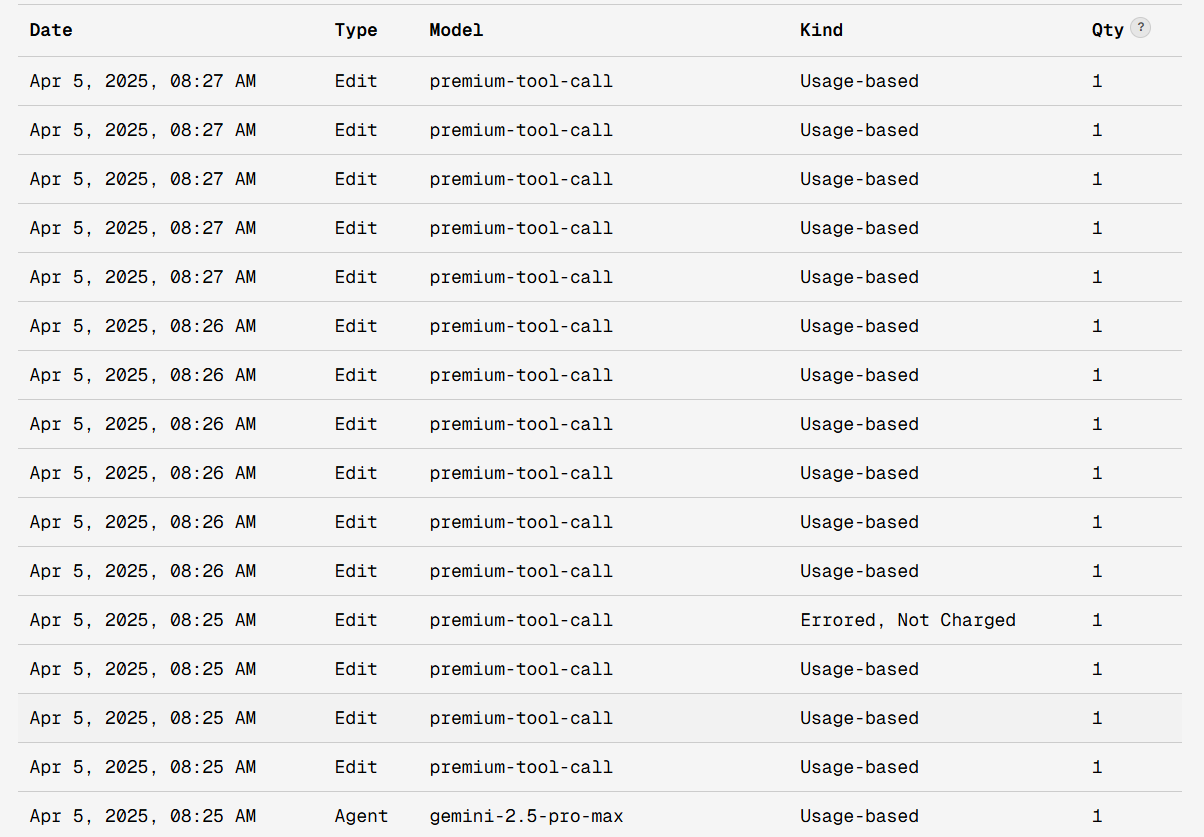
CURSOR IS A LEGIT FRAUD TODAY
18 CALLS TO GEMINI TO FIX API ROUTE!!!
IT OVERTHINKS AND BURNS THE REQUESTS AT INSANE SPEEDS
1$ PER MINUTE IS ■■■■■■■ INSANSE
Unfortunately, we have only so much control over how the model behaves, so I can only apologise for the number of tool calls it used here.
As mentioned in the release post for Max mode:
For standard code edits, Cursor’s standard Agent is still the most cost-effective solution and would be more than enough for >90% of all the prompts Cursor sees.
We only recommend this model to those who can afford to test its capabilities without concern about the cost and will make use of its additional intelligence.
There is always a risk that the model will perform poorly and, consequently, be expensive. If you are not happy to take that risk, I recommend not using Max.
We are still working behind the scenes to improve the performance here, including working with Google to fix issues with tool calling on their end, but in lieu of this, please do not spend more than you can afford to on Max mode, as the benefit is not guaranteed.
Thanks for the detailed feedback here!
I think this cleanly splits into two points here:
The model performed better, and had better context prior to Cursor officially adding support
This feedback is valuable, and while we have tried to improve the prompting for Gemini to make it work better within the boundaries Cursor provides (e.g. how to call a tool, how to output a codeblock, etc), there is a risk this has an adverse affect.
Once all the hard bugs are ironed out, there will be a more fine-grained evaluation of how Gemini 2.5 performs generally, touching on the areas you feel have worsened, to try to optimise the prompt for maximum performance in these areas.
A “transparent” mode may be useful, but could run the risk of Gemini not functioning in a way Cursor expects, and therefore ends up with a worse experience. There is a middle ground here for sure, but we will prioritise stability over top-end performance first.
Why am I paying for a model that is free?
This is a good question, but the answer is that the model is not free, it’s just someone else footing the bill. When you use your own API key (which I would highly recommend while it is free!), Google is absorbing the cost of running the model to allow individual users to try it/
For Cursor, we have to pay Google their usual costs, just as we do any other model, so unfortunately have to pass that cost on to the users.
As I mentioned, I would recommend using your own API keys while Google offers this, and with a Pro subscription, everything should work as expected here. Max mode is also free when using an API key, and uses all the context available!
Please do share bad Gemini experiences with us, as we are really working to improve this experience right now. It is proving to be a very capable model, and we want to make sure Cursor is the best client to use this model with!
Regarding Unreliable Tool Calls:
Just as a short , general PSA, tool calls with Gemini 2.5 Pro have been pretty unreliable recently, mainly due to issues on Google’s end, but the reliability should be much better from now, and keep improving moving forward!
It is much more convenient to use any AI to polish your ideas than to write so much content by yourself. I did this too , and most people will do the same, after all, English is not my first language.
by transparent mode do you mean calling Gemini “as-is” without the additional Cursor wrapper?
For certain models that don’t work as well with tooling (or work better without requiring tooling), it might make sense to do something like:
Use the model “as-is” in Ask mode
Instead of running tools, run the commands (grep, etc) in Cursor locally and pass the entire output to the model. Gemini’s got a big enough window to reliably handle it
Provide the output, even if user has to apply it themselves, at least it’s still in the IDE
Appreciate you explaining the work being done to integrate Gemini models.
I must complain as well. Just spent 2$ to have Gemini Max completely rewrite unrelated stuff in the project imports and make code changes that were excessive for a very small feature request. This of course after it went asleep first few tries but still ate 30 cents for not replying anything after Thinking.
And then, I asked it again to implement the same feature and it just did with minimal changes and zero compile errors because I asked it to do minimal changes and not touch unrelated things.
Funny how that works, does the Cursor system script not have things like “don’t mess things that already work, don’t delete existing comments, don’t make new compilation errors, don’t completely upgrade import versions every time you feel like it”?
Tried using Gemini-2.5 Max & Claude-3.7 Max-- with both it thought and began executing the code and then inexplicably stopped without an error before actually making any edits. Luckily I haven’t racked up too many charges but I’ve wasted about $3 on useless calls, making me not want to use the feature, and hesitant to use it in the future.
@vibe-qa The Max modes are tuned for very high-entropy changes, where it requires a lot of context and intelligence for the model to complete a task.
However, the Max mode is not a golden bullet, and unfortunately is just as likely (if not more in some cases!) to make mistakes, errors and output non-productive code suggestions.
@jjjjjjjjjjjjjjjjacob There was a now-fixed bug on Google’s end with Gemini which caused it to give up without completing it’s sentence, or returning an error (both from Google to us, and us to you).
We’ve tried to refund as many of the errors as we could detect, but this should be much better now. Feel free to drop us an email at [email protected] and we can help out with the wasted credit if you continue to have issues.
Thanks for getting back to me. I’ll jump right in.
Let’s talk model costs:
This is obvious to me and I understand Cursor incurs costs from Google. My point about the model being “free” was simply referring to the current state where Google is footing the bill.
…having said that …
Model
Input (per 1M tokens)
% diff
Output (per 1M tokens)
% diff
Gemini ≤200k
$1.25
-58%
$10.00
-33%
Gemini >200k
$2.50
-17%
$15.00
0%
Claude 3.7 Sonnet
$3.00
—
$15.00
—
Gemini’s input cost is less than half (58% cheaper) than Sonnet’s base rate, and output cost is 33% cheaper ($10 vs. $15 per million tokens) — up to 200k tokens
… Is the plan to keep the 5¢ per request?
Even at the million-token level it’s still cheaper than sonnet ($2.50 vs $3.00 per million). Let’s assume it will be even lower when google announces their prompt caching costs.
I’ll admit — you guys face a unique challenge where your user base is more cognizant of your hard costs than really any other scenario/industry/product I can personally think of.
Now, I’ll touch on a few other points:
MAX + Context Usage:
See, this is exactly where it breaks down for me. This hasn’t been my experience. I’ve specifically tested this using methods like Repomix to stringify my codebase, carefully tracking token counts provided versus tokens actually used (via the “…” counter).
My testing consistently shows that the context I am providing is being truncated — even with my own API key and MAX mode enabled.
The token usage varies but is practically always lower than the context I explicitly provide. So, when you say “it uses all the available context”:
what does that specifically mean in practice, given this discrepancy?
Is there some other factor limiting the context passed to the API?
Is context still being sliced and diced / semantically filtered?
Is context in any way shortened in MAX mode?
“Passthrough” Mode
With respect, you imply that a mode specifically designed to bypass context window truncation and any semantic editorialization would inherently compromise core functionality seems somewhat misplaced.
Can you confirm explicitly what kind of functionality risk you foresee if Cursor introduced such a Passthrough mode?
My suggestion for a “Passthrough” mode is precisely about:
letting the model handle the raw context provided
without intermediary truncation/semantic filtering of the provided context.
This shouldn’t inherently break tool usage or basic interaction formatting.
I think the context could be augmented towards the bottom of the context window with semantic helpers.
For Example:
Keep in mind, I obviously don’t know what you’re already doing, or how you guys are constructing the message array — so apologies if i’m making an asss out of myself (note: I’ve probably past this point long ago, so I’ll continue)
/* full context provided */
<FullUserProvidedContext>
[full provided context]
</FullUserProvidedContext>
/* augmentation */
<SemanticFilePathSuggestions>
// Here are the files to focus on, they can be referenced in the raw context
- (file1)[src/file1.js]
- (file2)[src/file2.js]
- (file3)[src/file3.js::38:40]
</SemanticFilePathSuggestions>
// # Tools use :
// Assuming (based on your implication) you currently have this section or similar in system message.
// depending on the model, tool definitions tend to work best as self-contained JSON schemas
// with either examples or really thorough definitions included throughout the JSON schema
// vs. placing explicit instructions in either developer/system instructions.
// Different models obviously behave differently.
I’ll acknowledge my example omits one big point and this may be where things break down: The treatment of context during the course of Agentic Triage.
Obviously things become more complicated there I can make assumptions around how you guys handle this but they all still lead me to believe it’s a different model handling how this is done.
Beyond the above, I’d still appreciate clarification on the other points raised:
Context Transparency:
Is there currently any direct way for me, as a user, to see exactly what context was sent to the model for a given query?
If not, is there reluctance to provide this transparency because it’s considered proprietary “secret sauce”? If so, I’d strongly suggest reflecting internally on ways to build defensibility that don’t sacrifice transparency (and confidence/trust).
Redundant Tool Calls:
Any insight into the “read file” calls for already-provided context? Can you confirm that this is either a bug, or that cursor is still truncating context in MAX mode?
Thanks again for engaging openly. I’m invested in Cursor’s success and want to ensure transparency remains central.
Then why did you guys nerf the chat. Claude 3.5 had the long context chat mode of 200k , but you guys took it away for no reason and as usual ignored the plight of your customers.
I appreciate the clarity on the pricing difference between Claude and Gemini. We have individual contracts and pricing with each provider so it’s often not as clear as this on where pricing lies, but I will feed this back to the team to see if there’s anything we can look at improving here
Context provided to any model always jumps through some pre-processing steps, but with Max mode enabled you can be sure you are getting the best possible experience of that model within Cursor. We still do not send files to a model just for the sake of it, and will still somewhat “curate” what is being sent to the models, as they still perform better given only what they need and nothing more, but the criteria is much lower for Max mode, allowing more of your files to make it into the final prompts to the LLM
By a “transparent” mode, I refer to a way to strip out our curation step, instead doing as I described above, sending the whole contents of many of your files to the model without any of Cursor’s guidance or prompting. The issue here is, without our prompting, the risk of the models performing worse or failing to interact with Cursor in the correct way is much higher, and could quite possibly lead to a less reliable experience for many users
We don’t have a way of seeing what is eventually sent to the LLM, but we do have some ongoing work to improve this that I’d hope we can bring soon. As context is the name of the game in getting great AI responses, more visibility on what makes it in here would allow devs like yourself to lean into it further!
It’s unfortunately down to the models to decide what they do, and they often do not fully get the semantics behind needing to read a file that has already been provided. We try to minimise this where we can, but models like 3.7 do have a risk of doing this that is hard to avoid.
Regarding the muted posts, this is an automated feature of the forum which tries to hide posts that have been reported by other users, to ensure things remain clean and civil and it unfortunately looks like your post got caught in the crossfire.
I believe the editing steps it describes are sufficient to allow you to still resolve the hidden post - although annoying, this is a “greater good” feature that we can’t afford to turn off at this time.