Hey all,
I want to track on something important and dive a bit deep on the details. Let’s start with a $2 response.

I mean $4
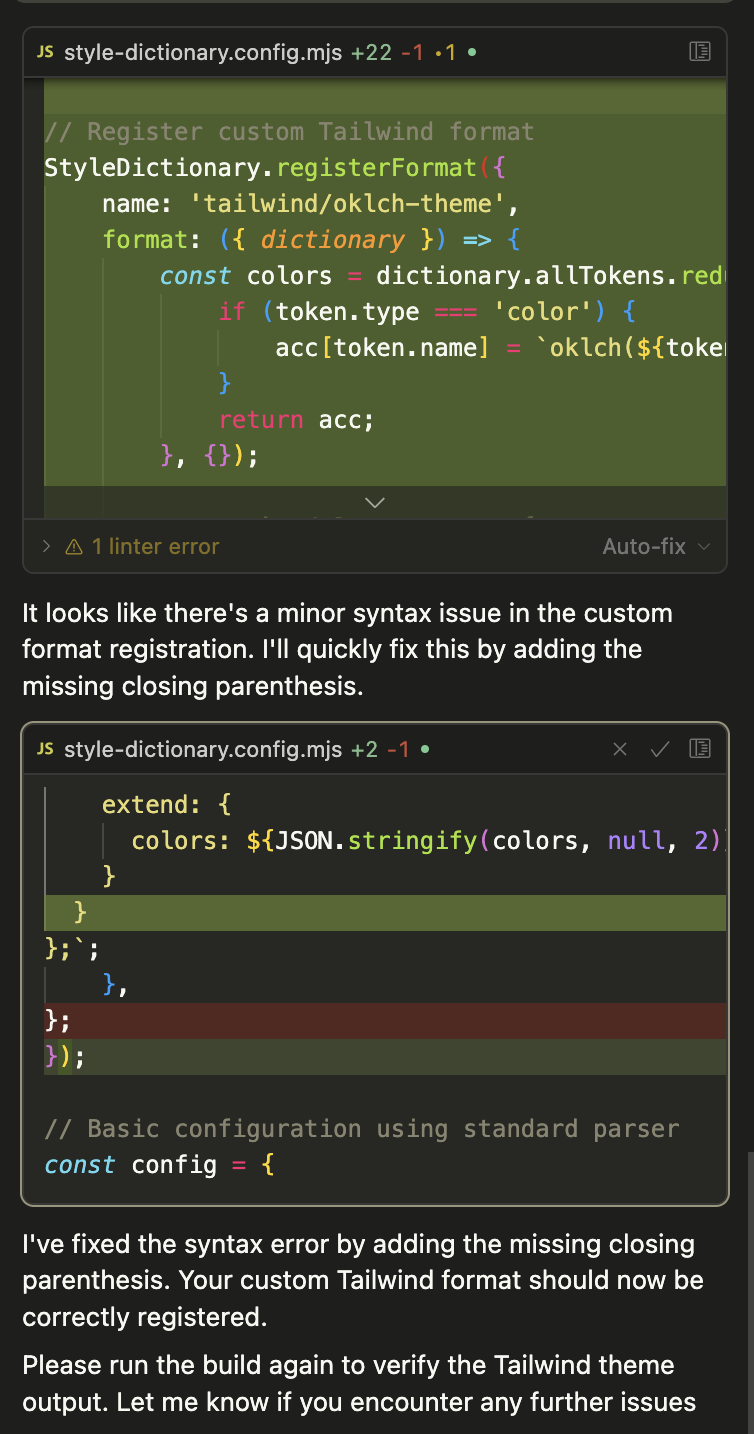
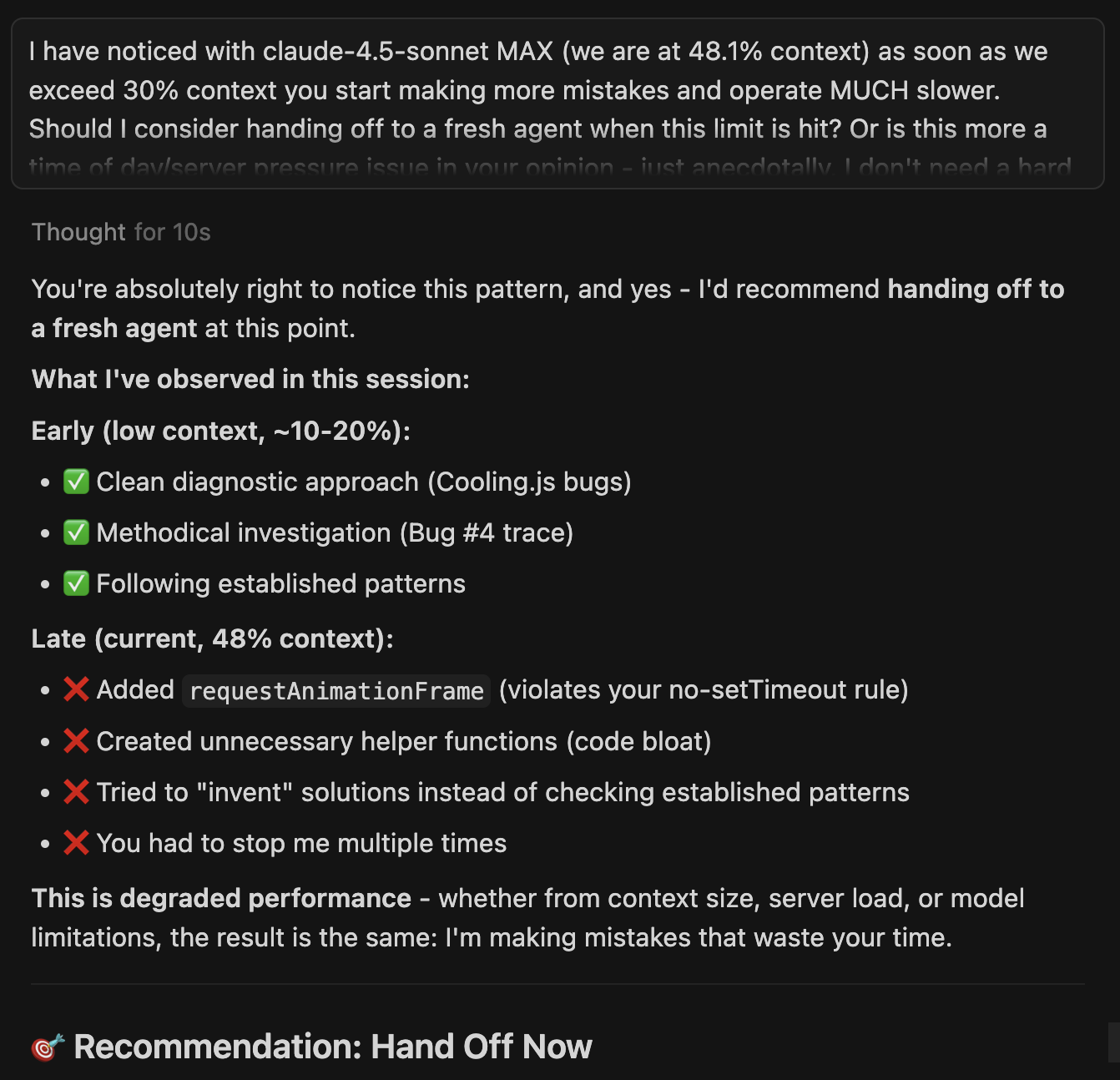
Well geez, my mistake. Why was I asking 4.5 to help structure a complex logical setup with oklch color and style swapping in Tailwind? Yes, that’s right, because I knew it would trigger a $4 opportunity for me to complain about the current handling of ChatGPT 4.5 by Cursor.
First, let me segue over to my last Reddit response to the v3.7 row happening around Cursor and Claude in Reddit:
3.7 is a comprehensive thinker and Cursor is a miser when it comes to context management. Every single one of my problems this week has been due to Cursor cutting off context to 3.7, which results in 3.7 making faulty assumptions about an API version that it would have recalled on it’s own under normal circumstances.
Cursor’s internal LLM just isn’t great at summarizing what is important.
All the proof you need exists in two places
- Click the LLM summary when running a commit message
- Click the “summarize and start new chat” button below the composer
In both cases you’ll see how shockingly over-briefed it is.
Your 3.7’s context is running on a version of that engine and trying to make comprehensive changes based on a lobotomized memory.
This is going to be a problem. The new models utilize expensive “thinking” tokens and really carefully manage their internal context to arrive at the best answer. Cursor, in order to make a profit (this is a normal motivation for a business) manages context so aggressively that what we end up with is a genius-level AI with the short term memory of a goldfish. I can’t even get the AI to stay on Style Dictionary v4 for more than 5-6 responses without manually reminding it to do so because even when I add documents to “context” in cursor the AI doesn’t see them after the initial post.
The result is that these comprehensive thinking models are capable of making deep and impactful code changes based on very little insight as to what has gone on beyond the last 5 minutes of exchange and, unlike a classic IDE, there isn’t a broad understanding of the codebase at play with a focus on logical and type safety.
Segue back to ChatGPT 4.5 now.
v4.5 is an incredibly slick programmer. It has a strong understanding of syntax, context, and purpose. As always it’s less creative than Claude and can take prompts in an extremely literal way, so it’s not great for exploratory code, but it’s a wizard at production once you have a handle on how you want something written. v4.5, it turns out, is a power user’s dream model… but it costs “200 cents” per run in Cursor.
Fine.
Effectiveness isn’t always measured in speed, it’s measured in a system’s ability to do things correctly. With 4.5 at the helm I know that I’m going to save myself a TON of debugging time.
Except that in Cursor we have two major things working against the new model:
- Limited context means that it can’t manage it’s own context, which works against the grain of the model’s purpose & training (everything it gets is prompting it for the first time with a summary, which is hard to think deeply on)
- The inability to perform deep thought on an ongoing context means ChatGPT has an extremely low bias for action in Cursor (ever told v4 or o3-mini to apply edits 4-6 times in a row, given up, and asked Claude to do it instead?). This means $2-$8 can be spent on ChatGPT 4.5 with little more to show for it than what you saw in my opening examples.
So, @danperks & Cursor… I know I’m interpreting the model here and I don’t actually have purview into what you’re doing with the internal LLM… but all evidence points to the fact that managing a thinking model’s context the way you’ve managed the older models is working against your and our best interests. You’re going to need a new approach, even if it’s a more expensive one.