For anyone disappointed GPT 4.5 won’t be included with their subscriptions, we’re likely not missing much.
Benchmarks don’t tell a complete story, but are useful nonetheless.
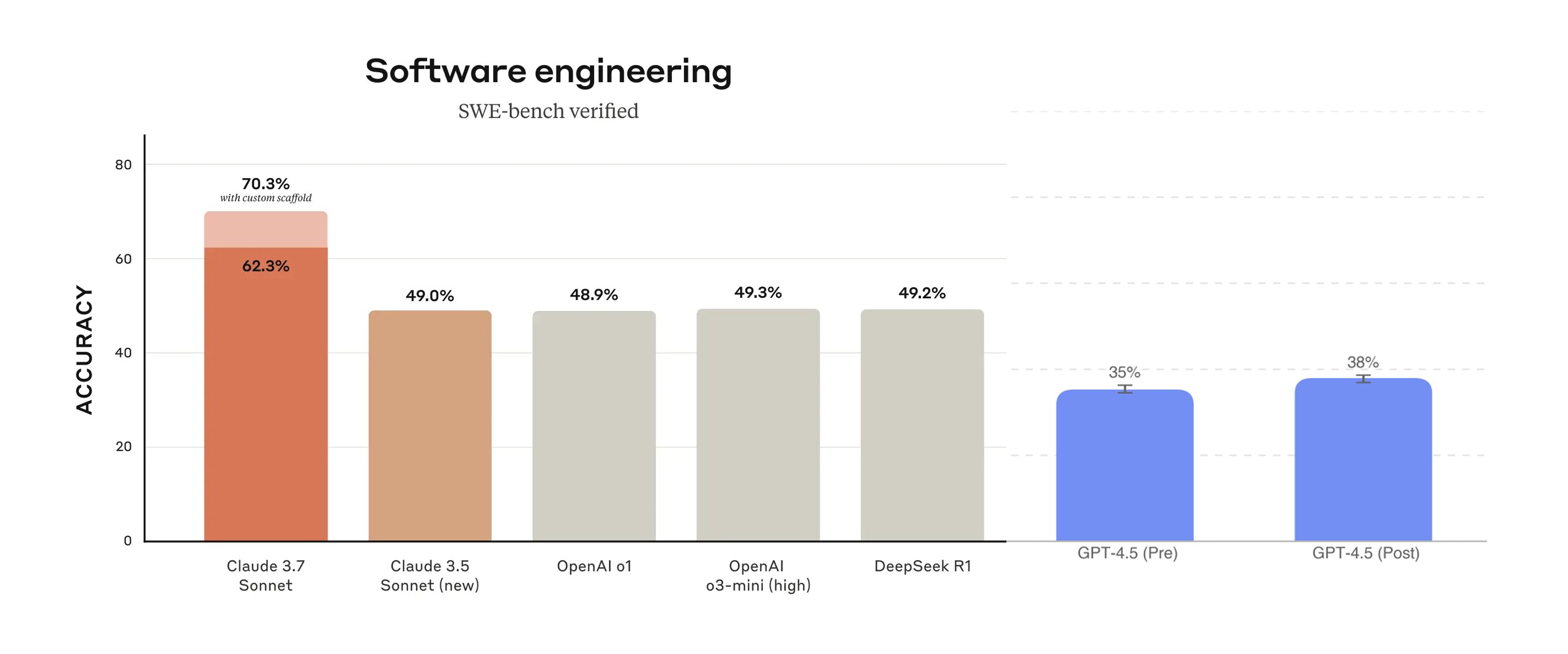
Haiku 3.5 isn’t included above, but scores 40.6% vs. GPT-4.5’s 38%.

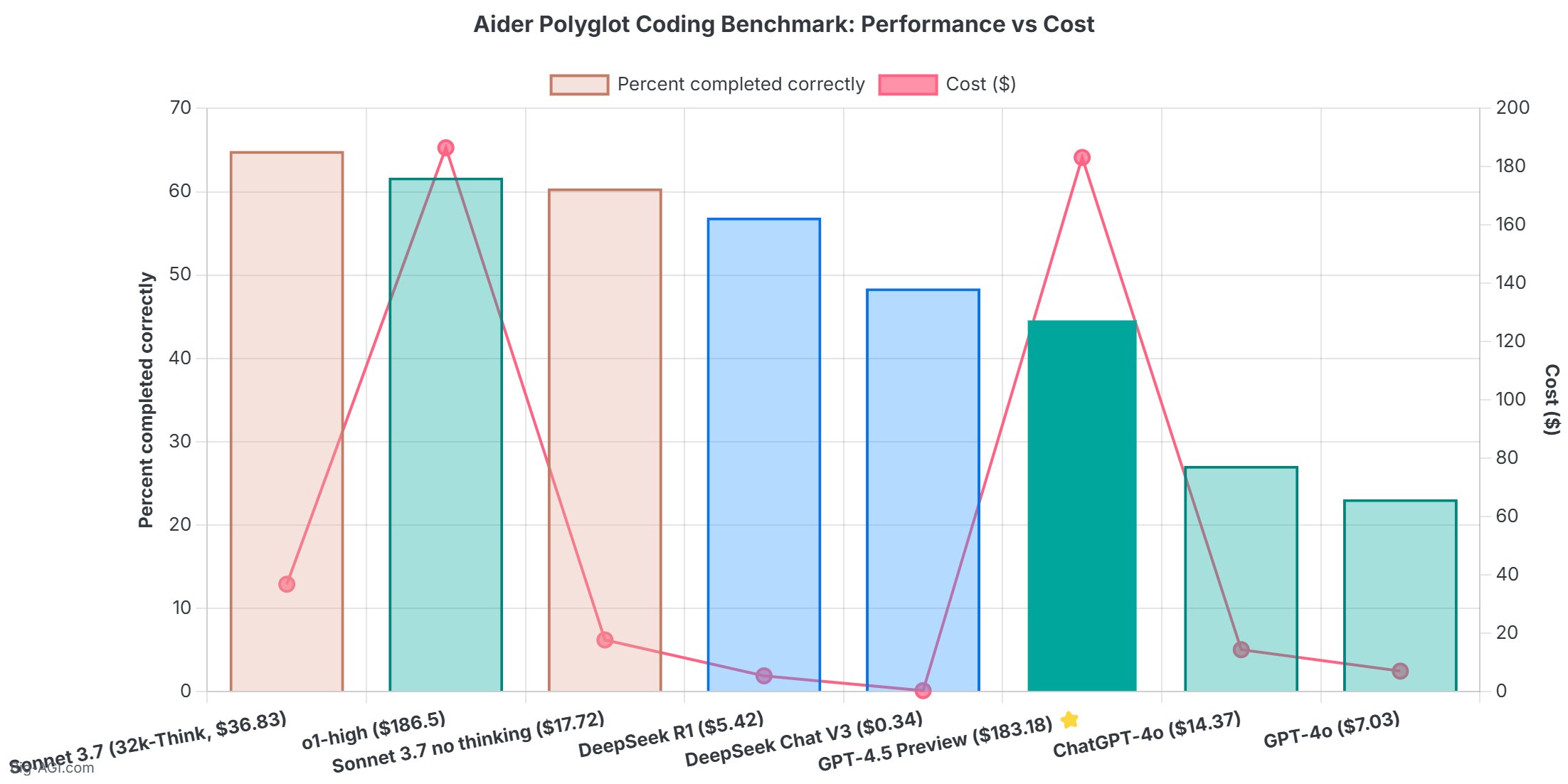
GPT-4.5 scores below DeepSeek V3 on Aider Polyglot despite costing ~540x more!
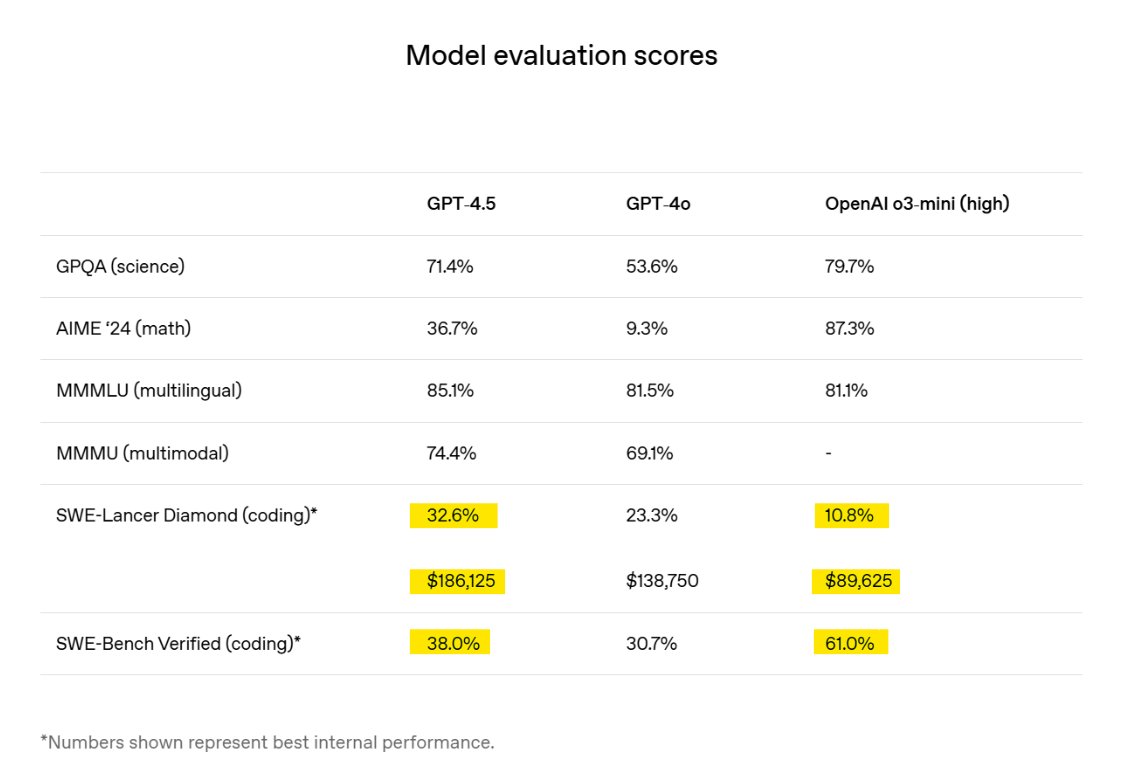
It’s clear now why OAI didn’t include o3-mini (high) on their recently released SWE-Lancer benchmark. ![]() They tested the old version of Sonnet 3.5 and it scored 36.1% ($208K.)
They tested the old version of Sonnet 3.5 and it scored 36.1% ($208K.)
OAI has also stated they may discontinue serving it in the API.
(it likely has ~5-10 trillion parameters vs. ~250B [175-400B range] for Sonnet 3.5)

If anyone burned the cash trying it with their own API key, it would be great to get a ‘vibe-check.’ ![]()