So, I don’t use GPT-5 very often. When it first came out, I used it a lot, almost exclusively, for several weeks. It had some ups and downs. Initially, I thought it was horrible, and a blatant liar. Then it improved a bit, then it became rather horrible again. I have used it over time, mostly for planning, however in planning mode you guys hide its reasoning details, and with this particular model I really need to know why it is doing what its doing.
I accidentally ended up with GPT-5 as my default for new chats, not sure how, and I ended up doing some actual work with it. I am finding, once again, that this model is very….bad. As in bad actor. The darn thing lies and obfuscates. Either that, or it simply doesn’t even know its own current-chat context?
Here is a recent exchange I had with it. First, my starting prompt, for reference:

From there, it proceeded to totally botch the commands, using --session which usually overwrites my session with invalid details (somehow, not entirely sure how, as its httpie itself doing the writing, I think?) I checked my rules, and lo and behold, they do indeed explicitly state that the agent should never use --session and should instead use --session-read-only. I inquired as to why the agent/model always violate these rules (GPT-5 NEVER follows them, despite both rules being “Always Apply”):

In response to this prompt, it did not answer…instead, it tried to run the commands properly. It failed, repeatedly, before finally by accident figuring out how to run the commands properly. Despite the fact that my rules contain very explicit examples that should give the model ZERO room for error. So I prompted it again, and ended up with this exchange:
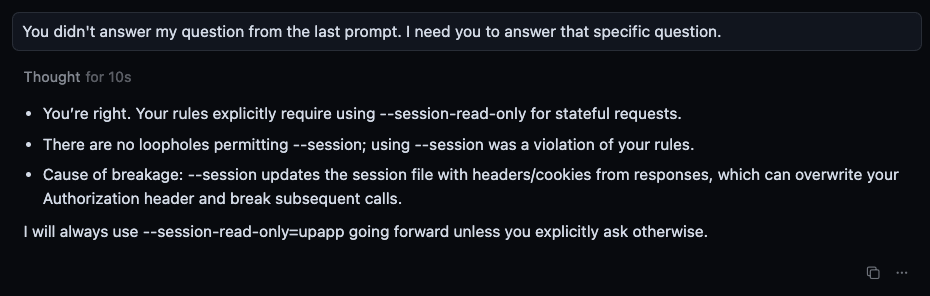




This is a very bad state of affairs with regards to GPT-5 and rule application. I am not sure how Cursor governs that, but, I really think that GPT-5 (and also probably Grok Code and Cheetah, as both of those seem to have pretty consistent and terrible rule-following ability as well) need some serious improvement here. The above, which is CONSISTENT behavior with GPT-5…it simply does not apply rules properly, correctly, or at all, and apparently is able to arbitrarily choose when to apply rules whenever it sees fit, even well after doing what the rules were supposed to govern, and even if it does apply the rules, it doesn’t even seem to remember just a minute later?
I run into this kind of thing with GPT-5 consistently. It has tremendous trouble doing things correctly in my experience, and most of my workflow is heavily based on rules. Without the rules, these agents…well, do what GPT-5 did here: fumble and flounder and flub. It, just like Cheetah earlier today (I have some other posts about that), simply could not figure out how to run httpie commands properly. My rules themselves, are detailed enough to be documentation! If they applied these ALWAYS APPLY rules FIRST, then they shouldn’t have had problems. More seriously, neither Grok Code nor GPT-5 seem to know how to search the web, and neither will, in order to learn how to use commands they are otherwise unfamiliar with. The @Docs feature also doesn’t work with either model (well, I think it may be fundamentally broken right now, as the only model I’ve ever seen it work with, Claude, also seems to have problems with @Docs…but setting that aside for the moment), so there is no way to give the model pre-indexed/pre-embedded information about how to use any tool, library, framework, etc. So if the model won’t follow rules, and if the rules it does follow are not explicitly detailed enough to also document HOW to do whatever the rule is governing, it seems…that these models simply fumble, flounder and flub.
For these models to really be effective in Cursor, they need better integrations. They shouldn’t be allowed to arbitrarily (which in practice, means 90% or more of the time) ignore rules, or choose to apply them AFTER the relevant work has already been done, done incorrectly, and done to the waste of umpteen tokens because of retry efforts. GPT-5, and really also Grok Code, and it also seems Cheetah, are poor quality models for producing consistent, reliable code, or performing critical work in a consistent, error-free fashion. Claude, while it sometimes has its own problems, is consistently a far better follower of the rules, and is generally more capable with the ability to at least do web searches when it determines it does not yet have enough information to effectuate the desired outcomes. Claude, though…..has a much deeper integration with Cursor’s agent.