Is there a way to debug what info is fed into the docs crawler? Im trying to add our internal docs and i dont think its working. Maybe because the site is a spa. Would love to know whats happening internally so I can just fix the docs
+1, would love to see the indexing in action if possible so I can format my docs correctly too.
I know they’re still improving the product but this feature would be killer if they can get it reliably working to process and index any kind of documentation website
We plan on adding a visualization of what it is the model actually sees when using docs in a future release. We’ll also have better docs management and auditing of text is shown for each page
For now, we use an HTML to markdown parser, then do n-gram deduplication across the crawled pages (to take out useless info like navbars). Finally, we use some simple chunking heuristics to break down a page into multiple ~500 token chunks.
The library name is node-html-markdown if you’d like to see what the raw markdown looks like for a webpage.
Ahh so if the docs are client side rendered its not gonna work?
What do you mean by client-side rendered?
Like its a create react app. So its all rendered using react. The html just has the script tag. So im guessing the cursor server wont execute the JavaScript.
@amanrs Thank you Aman, very helpful!
Are the requests made from the client running cursor or from a cloud-based service? Would it be possible to access non-public resources like Azure DevOps wikis or internally hosted sites?
I came here to mention that I think there might need to be some kind of user assisted check or something…
I want to play with a VSCode extension for my workflow, so I entered the url of Extension API | Visual Studio Code Extension API … 10 mins later it’s still learning. It’s following every link ( i didn’t know it did link following!), and there must be a heap going on behind the scenes. And there’s no cancel button…
They are rendered client side! We use puppeteer to control Chromium and run the Javascript.
Is there currently any way to control what links get followed? I’m trying to index Modules - io but it appears Cursor doesn’t follow the links. If I want it to index the actual docs for each module I have to do each one individually, and there are a lot of modules.
BTW Cursor is absolutely amazing – it’s the first AI code tool I’ve found that can properly assist with newer and highly complex libraries like Effect!
I still can’t get cursor to index Modules - effect
It won’t follow the links for whatever reason. This makes it more or less impossible to use cursor features with my codebase. Without the docs it gives completely wrong and non-sensical answers about effect code. It uses APIs that don’t exist, imports the wrong library, makes up APIs that were part of fp-ts two years ago, etc.
I still can’t get it to index the Effect docs which really limits the usefulness of Cursor. Without the docs I get wildly incorrect answers from the AI about any effect code (which is most of my codebase).
Hey everyone!
Sorry to resurrect a “dead” thread, but would love to bring the discussions back around here…
I took am quite seriously struggling to index some documentation - it’s not clear to me what the issues are, however, and debugging/fixing the issues around docs are tough/opaque, at best…
As this is a key feature, I’m sure it’s on the “radar” or whatever, but just wanted to know if there’s some additional help that can be provided here to try and diagnose to help this incredibly useful feature be… well, useful? Any ideas @truell20 et al?
Cheers to the team - love the product.
@jldb What documentation are you trying to index?
If I remember rightly it was Timefold’s documentation; but it’s one of a number of times I have had documentation crawling failed.
I would hazard to say that I don’t think a single documentation I have added manually has given the AI the information I know is in the documentation, but because the docs crawling is so opaque, I couldn’t really tell you why.
Sorry I can’t be more useful!
Why? What’s wrong with replying on-topic to a thread with new information?
Anyway, I have the same problem - how exactly does “Does” work?
What are the differences between “entrypoint” and “prefix”?

I tried to add this Docusaurus site but the only page added was the root page:

Then I tried to add another page to “Weaviate” but that doesn’t seem possible: clicking the pen icon only lets me edit the name, not add other pages.

I tried adding a separate page using the same name, but that didn’t work either:
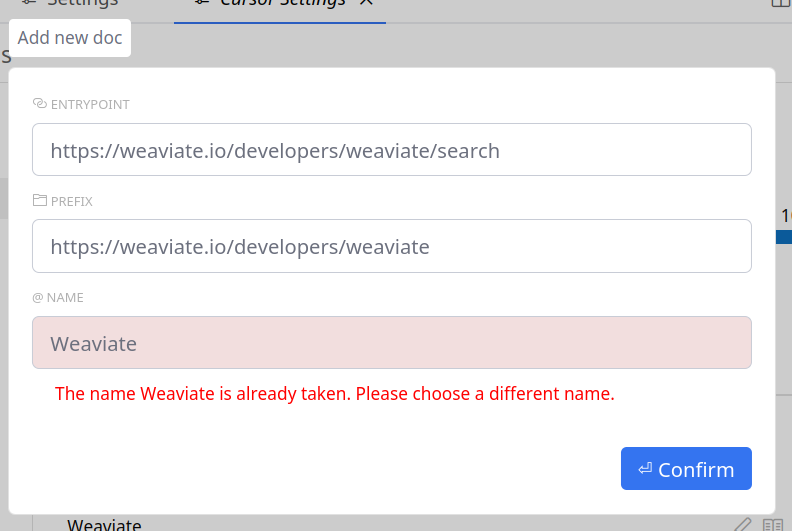
After changing the name, I saw the chat icon spinning but still only 1 page got indexed. Still only 1 page when adding another page under the Weaviate docs.

These pages are statically rendered: curl https://weaviate.io/developers/weaviate/manage-data | grep -o "Delete individual objects" will confirm.
Version: 0.35.1
VSCode Version: 1.89.1
Commit: a915e3254b1192ce240c078da83fc1768a6e3e90
Date: 2024-06-21T23:14:50.455Z
Electron: 28.2.8
ElectronBuildId: undefined
Chromium: 120.0.6099.291
Node.js: 18.18.2
V8: 12.0.267.19-electron.0
OS: Linux x64 6.8.9-100.fc38.x86_64
This is still a frustration. It’s unclear how docs crawling works, how it’s supposed to work, or how the settings change the behavior. Some clarification and docs on the feature would be much appreciated.
Docs crawling (@docs) is the highlight feature of cursor, looking forward to interface improvements :
- on first crawling request: percent completion estimate of the crawling progress across a site
- up front documentation about where the crawled and chunked docs are stored (locally/remotely)
- maybe have the option for a “docs stats registry” so one might be able to use some tests to determine if their stored docs are incomplete or out of date compared to what other users have for the same site [contribution to the registry/data collection would be optional, would need some way to score contributions to reduce the effect of spam]
This is still probably one of the biggest pain points in cursor. It’s a crapshoot whether or not you can get it to index the docs you want. If it works it’s great, if it doesn’t (which seems 50/50) there’s apparently nothing you can do about it. Some specific things I’d love to see for the docs feature:
- Make sure that indexing repos on github works out of the box. I’d like to add repos for libraries used in my app to get better answers based on the source of the libraries. Right now docs doesn’t crawl the source tree if you feed it a github repo link. Might be possible to work around with https://uithub.com/ but would be better to have “it just works”.
- Some mechanism to direct what pages get crawled. If the crawler fails to get to the correct pages at the moment for whatever reason there’s basically no way to index that documentation site and the cursor experience suffers, especially if it’s a less commonly used library.