I don’t think Cursor nerfs any model to sell MAX. The issue now for claude 3.7 is that the context quite small, and even MAX has a bigger context but still less than Claude 3.5, I still use Claude 3.5 for Agent and it works quite well.
Also, I believe when the app (Cursor) becomes bigger, issue will come, we just need to wait and see how Cursor solves the problem. Will they choose to provide a better service or keeps increasing price with bad products just similar to how GC starts to increase their price.
IMO, I believe Cursor still does well, it is more about the AI models or AI providers. Therefore, we can keep complaining about the fact of “stupid answer” from new AI models, however, we need to understand limit of context is an aspect that we need to consider for this topic.
I have used Claude 3.7 (or MAX) or Gemini pro max, honestly, they don’t provide any qualified answer.
I believe Cursor or AI now is developed too fast, and we are expecting a big jump better each model, but yeah, I think we should not expect it like that too much as Cursor is doing much as they can, I just hope they don’t increase the price without improving the quality.
I’m not sure what the gradation of models is, but Cursor as it is now, is barely useful (I have not tried MAX though). It keeps forgetting what we were doing (what it itself did just a minute ago) and does junior level mistakes (of junior with dementia). I’m seriously considering to switch to something else.
I’ve had this “nerfing” suspicion too since the release of 0.47.
It’s really sad because Cursor was my introduction to desktop app development (I come from front-end web dev).
At this point, it’s only my warm memories that tie me to Cursor, not its superiority in usability and value proposition.
It’s not so much about expecting a bigger jump forward, but that Claude’s output very suddenly dropped to pre-GPT-4o levels: When it adds new features it breaks old (working) ones, gets stuck into erroneous loops almost immediately.
Seriously, prior to 0.47 I built a pretty flawless system that allowed me to develop without returning to checkpoints to edit my prompts, simply by logging every error and its cause (this prevented getting stuck in loops) and by writing validations for every unit of progress (task, phase, feature, etc).
Since 0.47, it can’t maintain the error log, and it “forgets” to write the tests, and just moves on to the next task without having tested the last, resulting in potentially building faulty code on top of faulty code.
I’ve come to the same suspicion about Cursor potentially nerfing models. I’m a paying customer so I don’t wish my suspicion to come true, but goddamit, MAX mode behaves exactly as I worked with Claude 3.5 pre-0.47 and now post-0.47 Claude 3.5 is a demented triggerhappy intern-level script kiddie that can do a “close approximation” of what I asked but breaks other things on the way to completion.
I genuinely feel betrayed by Cursor, but I’m a bit delusional about it and I’m hoping they will “return”. Though my hope has been dissipating in large increments week after week.
From my experience your problem is common to us all and you may find a solution by understanding the issue:
Initial project is built flawless, it grows and LLM responses start to hallucinate or not remembering
New models introduced in Cursor are ‘dummy’ and ingest any context you throw them, Cursor refines them to get specific context and improve their responses
Both create a situation where you feel Cursor is nerfing models as you’re using unoptimized prompts, I recently refactored 4k code with only 2-3 errors and about 30 prompts(check my VSA topic), yesterday refactored 1k file with 1 error and 7 prompts, Gemini even surprised me optimizing logic of two loops and solving possible errors I didn’t thought of
Hey, sorry if I miss anything, but to try and answer some of the points here:
I’ll talk to the team regarding the Gemini 2.5 Pro non-Max context window, as it does seem a valid point that Gemini tokens are cheaper than Claude, but may be a reason why we’ve aligned it with Claude 3.7
We’ve actually just released DeepSeek v3.1, but Quasar Alpha can not be added yet, as we’d be unable to guarentee the privacy of user’s data
We are working to be better at our custom communication, but we are a small team and are growing as fast as we can! This will hopefully improve as time goes on.
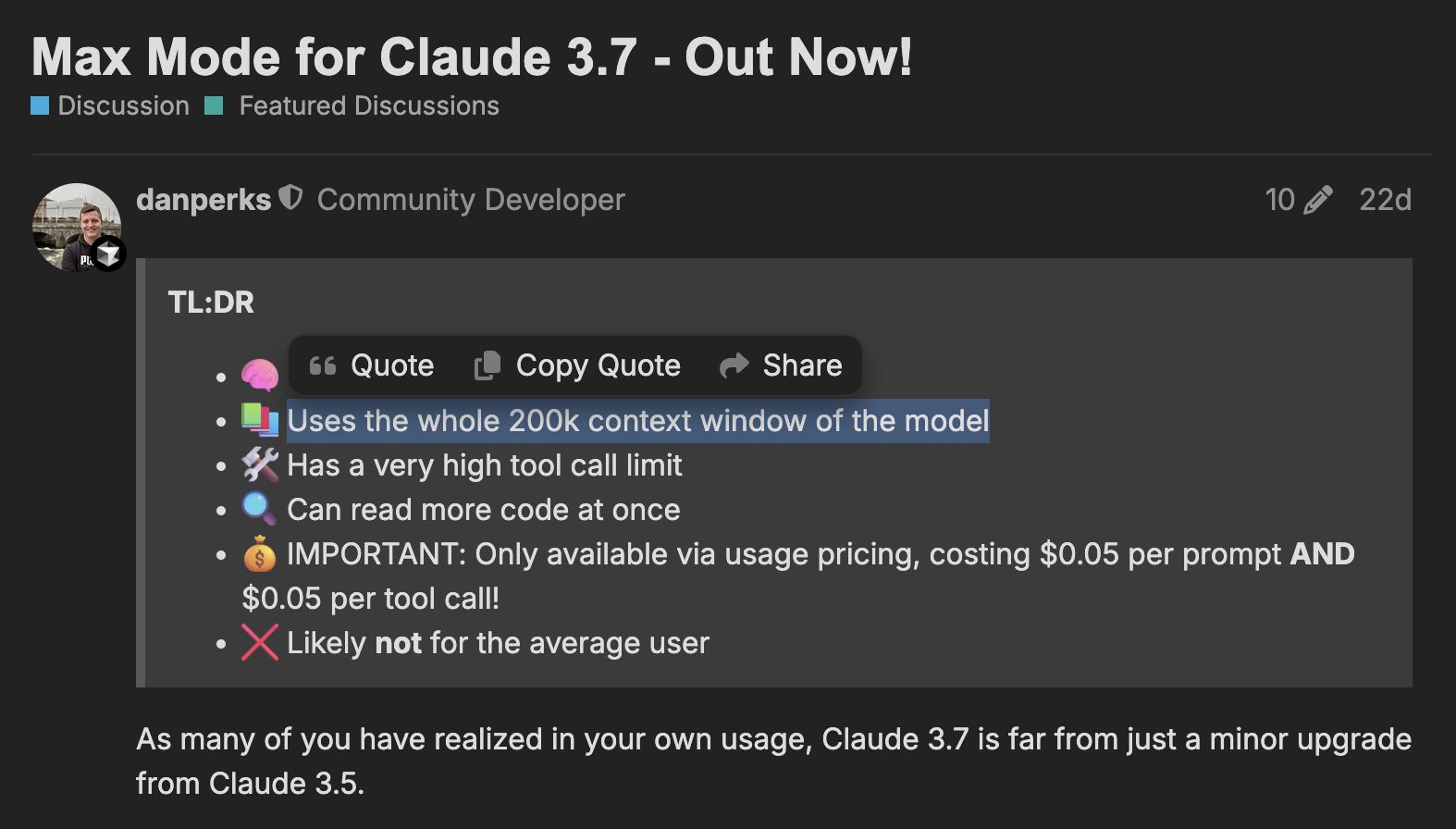
While Max is still fundamentally the same model underneath, the additional context and tool calls does unlock some top-end intelligence that is likely not possible with non-Max as it would require more context or tool calls to complete
Gemini Max does allow the 1m context window to be used, although the real performance of using up all 1m is likely not as good as 200k tokens, for example
We’ve not made any changes to Claude 3.7 with the addition of Max mode - the model leant itself to higher-context situations that wouldn’t be viable within the standard plan, hence the creation of this feature. We still often recommend Claude 3.5 as the better model for working in large codebases, although Gemini 2.5 Pro seems a very capable model too!
The models forgetting what they have just done is a side effect of the models more than it is Cursor. Max mode may help to give the models a large working memory, but this only goes so far. Try getting the Chat to write a running changelog into a file that you can @ every so often, to keep it up to speed!
We are dead set on making Cursor an amazing product - this is our singular motivation, with the only criteria being that we can remain viable as we do so.
To summarise, no “nurfing” or degrading changes have been made since before the release of Max mode, and likely long before that. Context windows have grown, we’ve continued to work to improve the in-app experience and added more options for users who are willing to spend extra to extract the last 3% of intelligence out of the models.
We really care for the quality we put out and will undoubtedly make mistakes, introduce bugs and not always step forward with perfect execution, but I do hope our passion for Cursor will prove successful, and Cursor will be a great experience for you all moving forward!
We appreciate all the feedback, and encourage you to continue to provide it - even if we don’t reply, it still goes to directing the future of Cursor
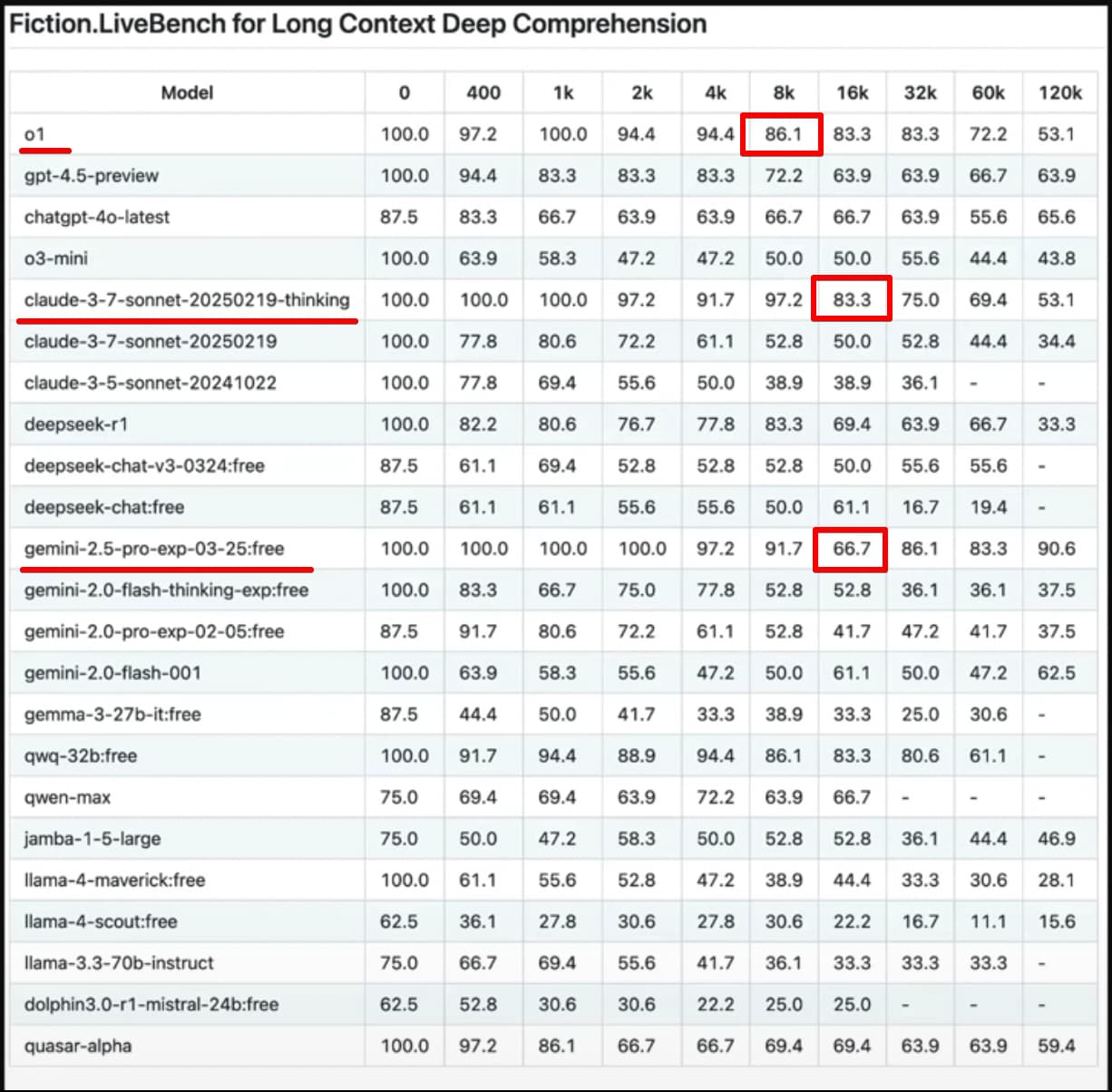
After 16k of tokens, ±600 line of code all models start missing up to 1/5 of code understanding. All those max models may be good for asking questions about code but I am not sure it’s smart to rely on large context windows.
From my experience in 90% of cases the best model is sonnet 3.7 thinking as it has greater context undertanding up to around 400 lines of code at 97.2%. But you need to use RIPER or similar “mode” to limit it’s scope of work.
For vibe coding I use gemini as it gets up to 90% of context at 120k. So there is a chance it will spot things that anthropic will miss.
Without understanding difference on context window between models it’s hard to predict what model and context when to use.
One trick I have found: Use cheaper model for context building when there are dozens of toolcalls to read the codebase and then use max model for planning and writing code.
It would be great it cursor charged context building (reading) tool calls at cheaper cost like 1c per read. as input tokens are cheaper. I am ok paying a few times more for thinking/output tokens, and write tools (codeblock, edit) use. I feel all models are good at context building and we do not need MAX for that.
sorry, but doesn’t looks true.
in the cursor model page is clearly stated that Claude 3.7 has a maximum of 128k context window in cursor, and you can use 200k (that is the one offered by Anthropic normally) only if you use the MAX model.
this is a shame if true.
you’re actually nerfing the models.
I agree and just wanted to throw in my thoughts. I noticed that in the beginning of a project things are great and can speed up a huge part of the prototyping but once I get into the weeds things are forgotten and broken as I go on. New features re-write old ones I didn’t ask for modifications on and even brings back bugs that were already fixed previously in the project. I will try the suggestion of having a file with changelog for reference and general rules. I did notice that repeatedly asking to refer to other project files or readme’s helped a ton. However, 500 fast requests go really quick when you’re trying to debug and it keeps adding more bugs in a large project!
The more newer versions I use, the more worst its gets. So personally I dont believe any “Nothing has changed” stories from the developer.
Cursor has good potential (or atleast it seemed to be). I definately dont even believe my requests are using claude-3.7-sonnet when selected, because I have used that before with other tools like LiteLLM and LibreChat and it is awesome. And it was awesome even on older versions like 0.45 and to some extent on 0.46. Now its horribly screwed up!
It hallucinates extremely bad! Tells me one thing, does another…looses track midway far more often. Uses 25 tool calls in seconds reading non-relevant files and that too in chunks and does nothing meaningful.
Its a wormhole to just get you to use your fast credits ASAP, getting you into their newly introduced “usage pricing model”
Many times, it just hangs (sometimes recovers after a min or so - yeah, thats fast premium request ), errors out but says User aborted request and its usage is counted. God forbid, this happens on sonnet-thinking and before you know you are 10-20 fast requests down, without even getting any output.
Except for the first 1-3 chats in a new codebase, cursor goes downhill pretty quick with no results.
I can assure 0.47 has far more tool calls very unnecessary and performs quite poorly.
And I have coding applications with AI assistants for some time now, so its not like I dont understand how to use it.
This is ridiculous and probably RIP between me and cursor, for what could have been a potentially good tool. I still believe feature wise, from advertising perspective, its got the right set of features on paper, just that it performs so poorly and always worst than the previous versions, while increasing the cost.
First time poster here.
i was thinking it was getting more s****d also sometimes. And certainly with the circuses i have had with Cursor insisting it is living in 2023 and changing python package versions back and fort all the time. But seems i finally got it to be fairly smart. It just created a 48 point checklist to itself that it chewed trough without any interaction other than clicking resume a few times from a 2 line prompt.
But honestly it got a bit over enthusiastic i think.
as all of a sudden my simple mcp-pypi server that i made to keep it inline with the package versions apparently got:
Smart Invalidation:
Add explicit invalidation capabilities for specific packages
Continue leveraging ETags for conditional requests
Expose a user-accessible method to force cache refresh when needed
Prior to Claude 3.7, all models were “nurfed” in this way, as we found the less context often worked better than trying to cram as much context into the models context window as it could fit.
The same is still somewhat true for Claude 3.7, and also due to cost, limiting it to 120k tokens allows us to keep up great performance while still keeping it at 1 request per use.
There are occasions where more context would be needed, and Max mode is the opt-in solution for that, but there’s probably only 1/100 requests that would benefit from the additional context, hence why it is opt in.
We cannot offer Max mode for 1 fast request, the cost to us from Anthropic makes this not a viable option - doing it this way allows for those who don’t want to spend more to still use Claude 3.7 within a high performing environment, while still allowing those who want the extra 5% of performance to get it at the higher cost.
I absolutely guarantee that, excluding any extreme circumstance (a bug or an account flagged for abuse), you always get a response from the model you choose.
We do not have any functionality developed to switch out models for cheaper ones in order to save costs and if we did, people would just use a different tool!
Claude 3.7 as a model is substantially less reliable than Claude 3.5, and may of us still use 3.5 for more precise edits. 3.7 is more likely to go off track and hallucinate, as you’ve mentioned, but it is also more creative and intelligent when it works correctly! I believe this could be one of the major factors to the poor performance you have been seeing.
Many users here have great performance out of Cursor, a lot of which never interact on the forums as they just open Cursor and it works, but it’s very dependant on the kinds of projects you are working on, and what your expectations are for the tool.
Ok, thank you.
This is a much better explanation.
This should have been included in the original announcement post.
Keep in mind that we’re all developers, we need technical context to understand how and why certain decisions were made, especially when there’s a price increase involved.
If communication isn’t clear and complete, there’s a high risk the community will misinterpret things, like I did.
Something like this would’ve been much clearer and more transparent:
“Hey folks, we’re trying to pack a lot into both the free and pro plans, so some compromises are necessary. This setup covers around 80% of typical use cases and allows up to 25 tool calls per single request (note: using your own API keys, that would be 25 separate calls). For more complex tasks, we’re offering a ‘MAX’ mode, a no-compromise option, which costs $0.05 per tool call. You can still use the standard mode to gather data and then switch to MAX only for the final step, which uses the full context. We’ve done our best to keep the cost per call for the MAX models as low as possible, it’s roughly equivalent to using your own keys for most use cases.”