@jpedrorw what do you mean specifically? We show the pricing as per API cost and the model tokens as provided by Anthropic.
Just saw Sonnet 4.5 think for 4.5 minutes–on the same prompt that GPT-5-high did 4 minutes and 2 seconds. Very interesting–i’ve never seen Sonnet thinking models “think” like this…

you typed it wrong. sonnet
where are they?

- Anthropic model pricing is here: Pricing | Claude
- They also have a table version which breaks down pricing by model and cache interaction.
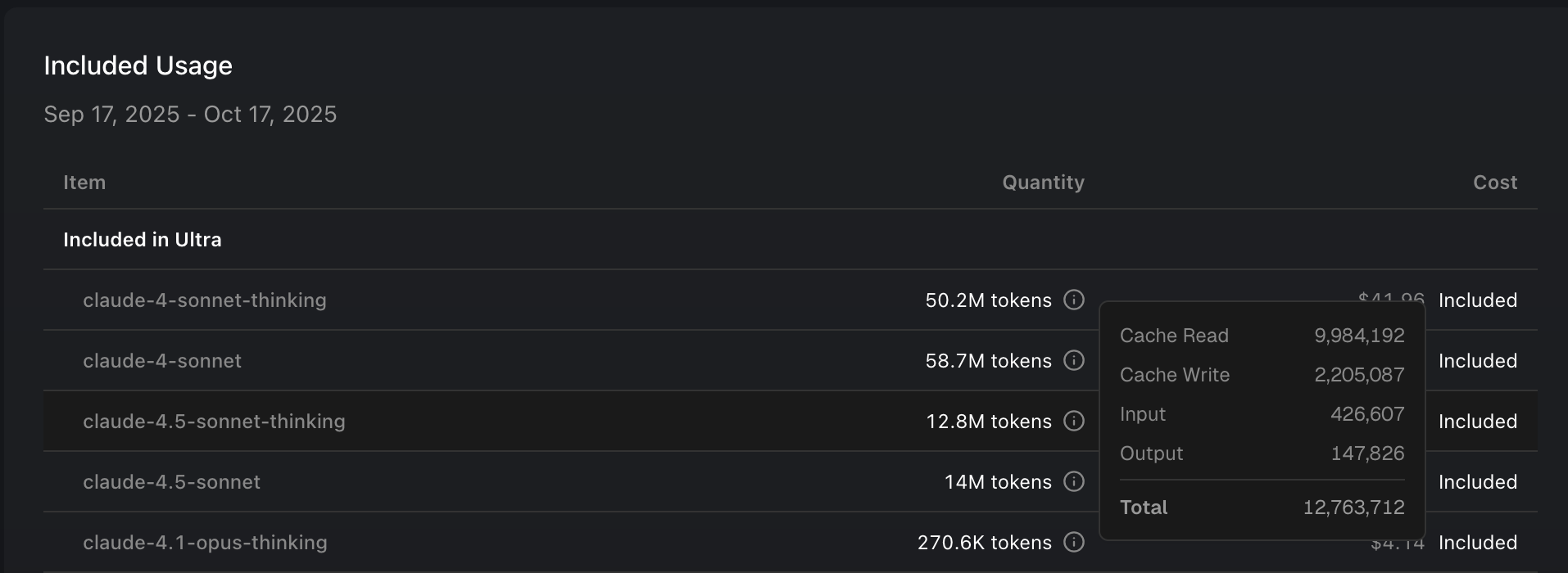
I’d assume Cursor uses the 5-minute cache TTL, but I don’t know that for sure. Can you post your full cost breakdown? I looked through mine, and it seems very reasonable:

For reference, here it is with the claude-4.5-sonnet-thinking token breakdown:
wtf
these prices seems off compared to claude’s official api prices.
cursor mysterious usage within “MAX” and double prices of context (who knows?)
serious dev big projects lol

I did some investigating, and the prices line up well to me.
Regular pricing (less than 200k context):
- Cache read: $0.30 per million tokens
- Cache write (assuming 5 minute TTL): $3.75 per million tokens
- Raw input: $3.00 per million tokens
- Raw output: $15.00 per million tokens
Then we have the “extended pricing”. My understanding is that when a message is sent with 200k or more total tokens, ALL tokens in that prompt are priced at the extended rate (2x the regular rate for input, and 1.5x the rate for output). In other words, the pricing doesn’t use a bracketing system. I could be wrong about this. Please correct me if my understanding of the pricing is wrong.
That means the extended pricing is like this:
- Cache read: $0.60/Mtok
- Cache write: $7.50/Mtok
- Raw input: $6.00/Mtok
- Raw output: $22.50/Mtok
I used this to estimate the cost for my 4.5-sonnet-thinking usage:
def cost(price_dollars_per_mil, used_token_count):
return price_dollars_per_mil * (used_token_count / 1_000_000)
# This is my cost, assuming I didn't use the extended
# context window.
my_cost = (
cost(0.3, 9_984_192) # Cache read
+ cost(3.75, 2_205_087) # Cache write
+ cost(3, 426_607) # Raw input
+ cost(15, 147_826) # Raw output
)
print(my_cost) # $14.76
This lines up - my actual usage was $15.12, but I know for sure I sent a few requests in MAX mode using over 200k context (i.e. higher costs).
I did the same calculation for you:
# This would be your cost, assuming you didn't use the extended
# context window at all.
your_cost_without_extended = (
cost(0.3, 236_128_856) # Cache read
+ cost(3.75, 16_819_680) # Cache write
+ cost(3, 5_743_956) # Raw input
+ cost(15, 1_043_174) # Raw output
)
print(your_cost_without_extended) # $166.79
~$167 would be way too low from the usage you showed, so I tried a second calculation assuming you used MAX mode the entire time with over 200k context:
# This assumes you used the extended (>200k context) window for every request.
# Notice the price increase for each calculation.
your_cost_with_extended = (
cost(0.6, 236_128_856) # Cache read
+ cost(7.5, 16_819_680) # Cache write
+ cost(6, 5_743_956) # Raw input
+ cost(22.5, 1_043_174) # Raw output
)
print(your_cost_with_extended) # $325.76
This is very close to your actual $321.48 usage. I assume my estimate is slightly higher because your real usage includes some requests under 200k tokens.
@jpedrorw If I had to guess, you probably stay in MAX mode and reuse the same chats for many, many messages. How often do you start new chats or compress the existing context?
Is it just me, or is Sonnet 4.5 really lazy? I can barely get it to finish my to-do lists properly it completes most of the items, but once it’s around 70–80% done, it just marks everything as completed and starts generating tons of markdown files, even though I explicitly set rules to prevent it from doing that.
Sonnet 4.5 is the best model after 3.7. I’ve set it to be the default on my Cursor Agent mode.
- It is very good at understanding what I ask of it.
- It implements the changes with utmost precision as a dev would (manual steering needed at times)
- It gives one of the best summaries of tasks or GitHub PR descriptions if you ask it
- Its output language just makes sense - I can understand it very well.
- Speed is good enough - I don’t expect 100+ TPS from such smart models.
It knows it’s context window - maybe it starts to slop once it’s too full? Devin guys gaslight it to have more context window ![]()
I slowly grow fond of 4.5 for ruthless reviews, and non-coding research (in CC).
I’m not getting a good result from 4.5 anymore, and the obsession with markdown file creation has become highly problematic. It’s also destroyed the last python module I asked a simple change for - how could such a good model go astray so far ?
“Such a good model”
It is horrendous compared to GPT 5. Just ask both models to created a dev plan for x project and then get them to compare the models. Claude will always praise GPT 5’s creation.
Who cares which model praises who’s… WHICH of the plans is actually BETTER, based on a HUMAN evaluation??
I find Claude Sonnet 4.5 to be better at most tasks, than the other models I’ve used a lot: GPT-5 and Grok Code. But that is from MY OWN evaluation. Who the heck knows what criteria a model is using to evaluate who’s plan is better?
From my own evaluations, Sonnet 4.5 is a darn good model that does a darn good job and produced code and plans at a quality I generally prefer over other models. As much as I use LLMs heavily to do my work now, that doesn’t mean I actually really TRUST them to actually have “good opinions”…I’ll take a human opinion any day over the opinion of a model. As advanced as these models seem right now, the human mind is still VASTLY superior..there is more to INTELLIGENCE than just access to knowledge. Remember what WISDOM is… Just sayin…
I got a lot of mileage out of sonnet 4.5 until last week, now I am running GTP 5 versions almost exclusiviely - I have Grok4 doing research and analysis, then i feed gpt’s the info and the build prompts for multi threaded progress farming …
Sonnet WAS good to me but something seems broken …
and now today GPT5 seems kinda broken a tiny amount too …
Whats the commonality ? Over engineered Cursor preprocessing might likely be the problem