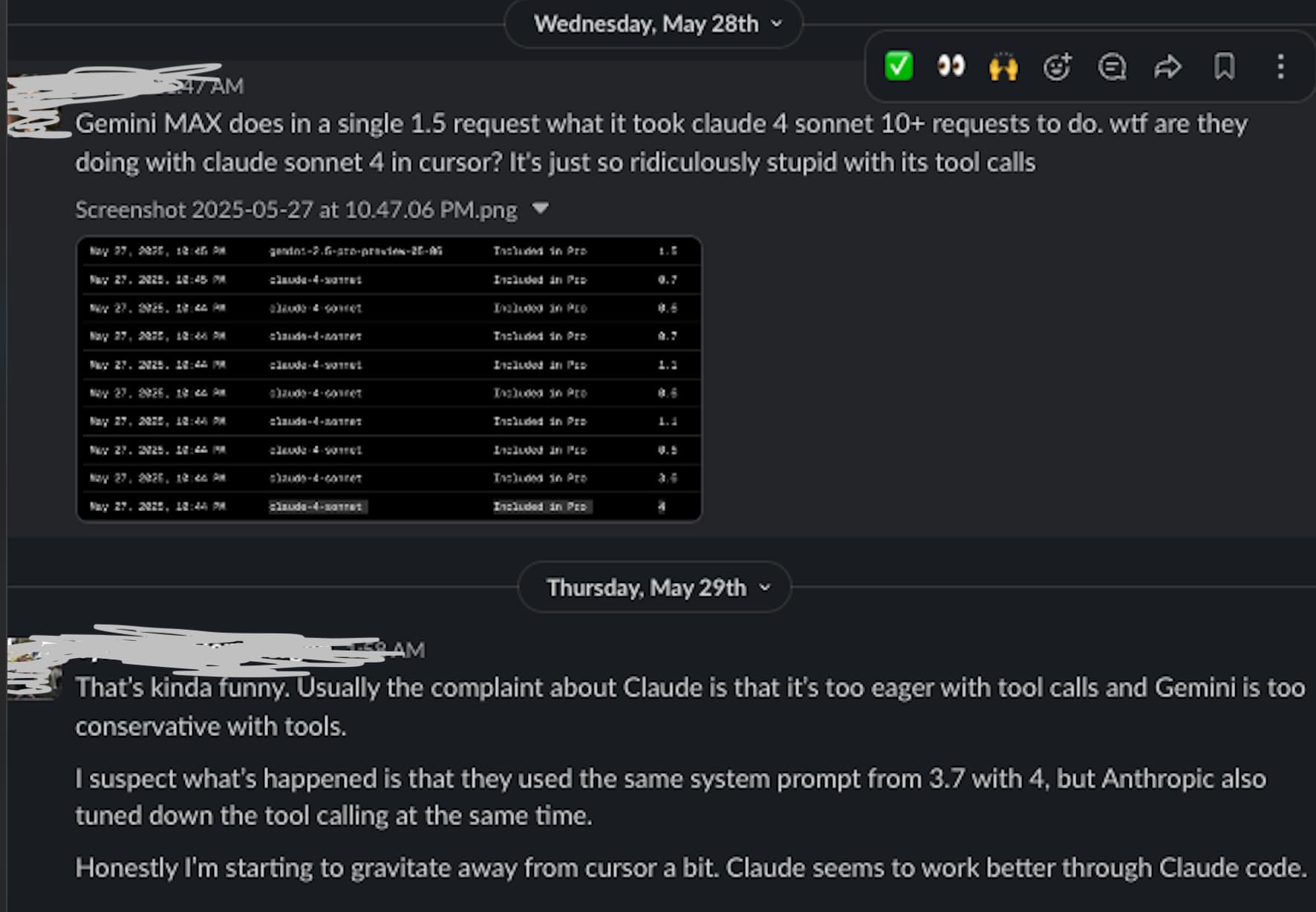
I have $4.00 left of my Pro+ subscription and 2 weeks until the month renews. It’d cost me the full balance to reproduce a requestId and I’d rather save this $4 for grok4 calls.
I get that @condor is a dev with 25+ years of experience. I have a codebase I own, I’ve put 1600 hours in this codebase, it thousands of customers…I mean to say I have an intuition on how Cursor agents work with it. I am telling you something is wrong.
Around .49x something happened with the tool calls.
I even have a screenshot from May 28th! when it was “request-based” pricing. I sent this to a colleague with more experience.
Here’s how to notice this issue → Implement some real feature work. Keep refreshing cursor dashboard between chat messages and note usages - see that some implementation changes cost $1.00-$3.00 with Agent Claude 4. Undo the checkpoint, switch to Agent Gemini have it run through it again. Note the price. Undo the checkpoint a 3rd time, then do Manual Gemini, ask it to output code for your to copy-paste, note the cost.
I would think I’m crazy but I look through this forum and see hundreds of people replying their own stories.
Tell me honestly, when so many users run through their Budget on the first day of usage, is your first instinct to think the users are bad actors or that the product may have a problem?
To do a sanity check, I used Claude Code for about 6 hours today instead of Cursor. I was intentionally extremely uneconomical with it. I would tag whole folders and give it vague instructions - it still came out only to $12.47 of API key usage.
Sure anthropic is expensive, but not that expensive. It’s certainly not the $30 I wracked up on the 5th of july and had to upgrade to Pro+ mid-feature
And why it even send complete code, search files, and other stuff to claude and repeats this more than one time and depends on cache, and yes its $0.13 for single request and someone may want to make 1000 of those per month, in regular cases this should cost $20 with code optimization and in current case it case it will cost $130
Used Cursor since mid-2023. Switched to GitHub Copilot 3 months ago, no regrets. Cursor’s become the F* overpriced fat-middleman. GitHub gives you real model flexibility without charging per breath. That “30x” plan? Cute, if you only code on weekends.
bruh no one only code on weekends, some ppl work on day of the week, i was asking if i get 0.04$ cents per request with claude 4 sonnet with the github plan
Bruh, I said code on weekends sarcastically, if you’re burning 500+ requests a day, even GitHub’s 30x won’t last long. And yeah, Claude Sonnet on Copilot eats premium credits. After your quota? $0.04 per request. Welcome to the metered playground. BURP!
in all my testing on my massive code bases, and empty projects, auto gives functional code about 15% faster on average. yea it isn’t perfect, the code is not professional, but you can run code to refactor it to make it more professional and even then it is still about 10% faster on average.
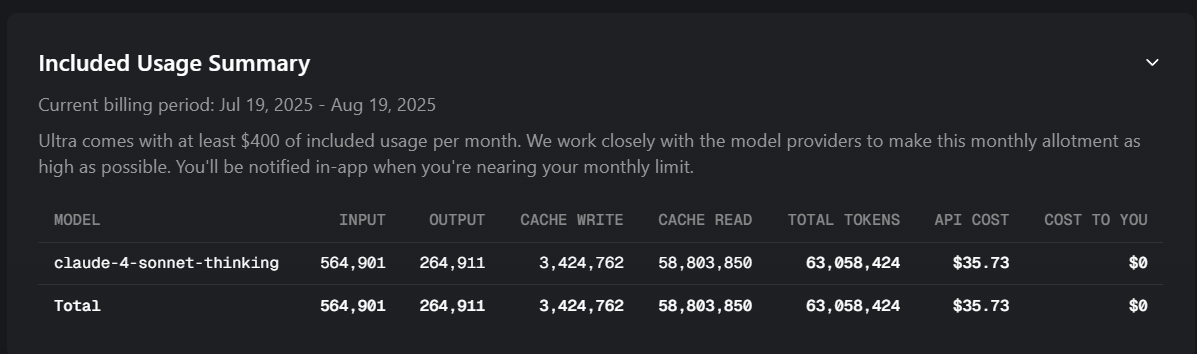
You guys are missing the issue. Cursor is using 3-4 million tokens for simple tasks that Roocode, Cline, Windsurf all complete for about $0.03 at about 10k tokens. Cursor processed 63 MILLION TOKENS! in half day when my Input tokens was only 564,901 and output token 264,911 This is a big issue!
I’ve literally used Cursor every day for the past year +, developed 12+ applications with it. I’ve used the pro, then metered usage pricing up until last month (for 7+ months with metered usage at same rate of use it would be $60/month in total usage every month this year). With this issue, with the same amount of use, I’m getting charged $35 for half a days usage! Look at my image, it literally processed 63 MILLION TOKENS! in half day when my Input tokens was only 564,901 and output token 264,911 This is a big issue.
@Illuminationx Its your fault, when you need to build full wikipedia clone that contains full human knowledge and uses 63 million token to build, then don’t blame cursor team
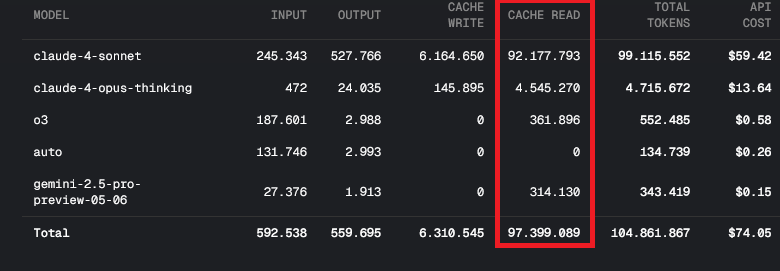
The issue seems to be with the cache read being out of control, generally cache reads are supposed to use only 10% of the API costs, now they are 70x the token size of the input/output tokens themselves. This needs to be fixed.
In my screenshot Input tokens was only 564,901 and output token 264,911 and read cache was 58 million!
I have a message here, but I’m afraid the cursor development team doesn’t want it to be seen by everyone. I performed prompt injection attacks on the Cursor agent using different languages under various models to force the model to reveal instructions that may lead to high token consumption. I discovered content that could potentially cause a lot of token consumption. But I can’t guarantee that it will definitely lead to the current token consumption we’re seeing. The content in the image is about instructions related to “maximizing context understanding,” and I’m sure this will help the model better understand the context, but at the same time, it could potentially cause massive token consumption.
@shechu Your post was flagged automatically as a billing question which is not handled in the forum. You received a notification about this with an explanation. Also I replied to your question in your thread now as its the first I saw it.
Only those afraid of the truth seek to silence.
It’s embarrassing how cursor is gaslighting everyone instead of explaining themselves, do they not know integrity within the public drops fast?
Why when I created a fresh project with no folders or files, no previous chats, I legit wrote ‘test’ and got charged 9850 tokens. But yeah, “change your chats”. Clearly that’s not the issue, cursor is the issue and you guys can’t admit to anything.
You are right, maybe at the end of the day its community of developers, and no one will see you guilty when you create a bug that eats token - aha maybe some will do - but most will not, but if you pretend that their is no problem at all, everyone will take their decision to find another alternative, or they at least will love to move whenever they have chance to