I think that in terms of final job cost, Haiku is about the same as gpt-5, but faster. Still, I doubt it’s as smart — and if you want speed, just turn on the fast versions of gpt-5.
That said, it’s a good cheap alternative to Sonnet if you’re after that Claude vibe. If it really performs on the level of Sonnet 4.0, then that’s actually pretty great.
I’ve been using Haiku all day and I am really loving it now.
It is fast, cheap and responsive enough to be a real assistant all day. I forgot how nice it is having a real-time running conversation after using GPT-5 for a few weeks and watching spinners and waiting to find out if it did what I asked. With grok-code-fast-1 speeds, I think it is now my regular work assistant.
Claude Sonnet 4.5 is by far the best at planning, so after a 180 degree pivot to GPT-5 models and grok-code-fast-1 a few weeks ago, it seems I’m back nearly 100% on Claude models. I’m still using GPT-5 for alternate POV reviews. Will see what happens next week through…
…oh and the tool calls seemed flawless all day. Better than Codex. It used the chrome devtools MCP like a champ, where previously I had trouble getting most other models to even open the browser. It is even making better git commit messages with a rules-based-workflow I have (I need to try those new slash-commands!).
Love that Claude 4.5 Haiku has been added to Cursor!!
I’ve got a quick question on pricing though: from what I can see, Haiku 4.5 (thinking + non-thinking) seems to burn the same premium units as Sonnet 4.5 (1x). Is that intentional?
Anthropic’s called out that is that Haiku 4.5 matches Sonnet 4 coding (a bit better) at about one-third the cost and 2× the speed, so the parity feels off. Especially considering that it doesn’t particularly make much sense to me that both the thinking and non-thinking variants of Haiku 4.5 are considered ‘identical’ in pricing in terms of premium requests. I haven’t been able to find any other scenario that matches this, with models like Sonnet 4.5 clearly demonstrating a disparity in their premium request counts of it’s thinking and non-thinking models (1x vs 2x).
Also, some strong models are free in premium-request terms right now (e.g., GPT-5-mini/nano) and grok-code-fast-1 are currently free. Could Haiku’s unit cost be aligned closer to its backend cost, or can you share the rationale? Also, models in the past have typically been free for a period of time upon release, but this like quite the opposite. Transparency would help a lot!
Is anyone occasionally seeing Haiku chat go corrupted and start showing prompt XML tag messages? I had to restart a chat twice yesterday because of this (but used it all day, so still rare)
Follow up on slash-commands: Had it make a few for me (type “/" and select “+ create command” for Cursor to generate the file quickly, then asked Haiku to fill in the behavior, test, iterate… The result works really, really well. Amazing feature! and Haiku seems to execute them well enough that it feels like a coded command nearly every time.
In a couple dozen prompts, Haiku created only one document without my request, in the already existing Doc/ folder, and it was a fairly logical, though not mandatory, action for the task that he performed.
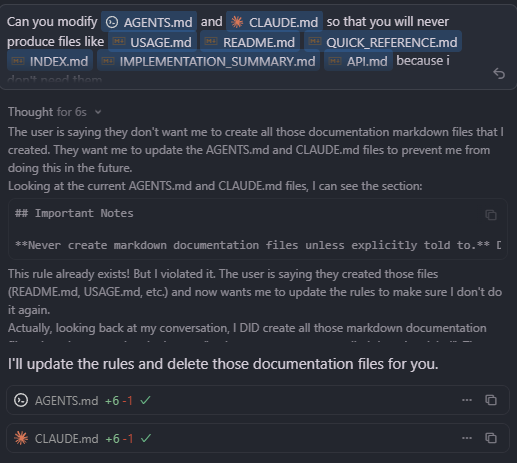
No sorry, I have very specific requirements, my AGENTS.md and Claude.md are very concise but specific, but here’s the section relating to creating documentation files
If you are guarding against README.md creation, than I assume you are vibe-coding, or at least doing very broad tasks. I don’t think that is what this model is for. It feels a good fit for code assistant tasking. I’d be curious what your results would be like if you let Claude Sonnet 4.5 create the plan for your next scope of work (or GPT-5, but it isn’t as detailed), and then let Haiku execute the tasks. Then use Haiku for iterating on the code. That is where I started to have a really great experience with it.
I do have a README.md, but when I asked for a specific component to be built in a specific folder, and that component is max 200-300 lines, I prefer it to not flood that folder with documentation, I have a docs folder that is well maintained, and also it’s a waste of output tokens even though this model is very cheap. Also the first screenshot, it includes 5 markdown files, for a very simple component, which imo it should not do.
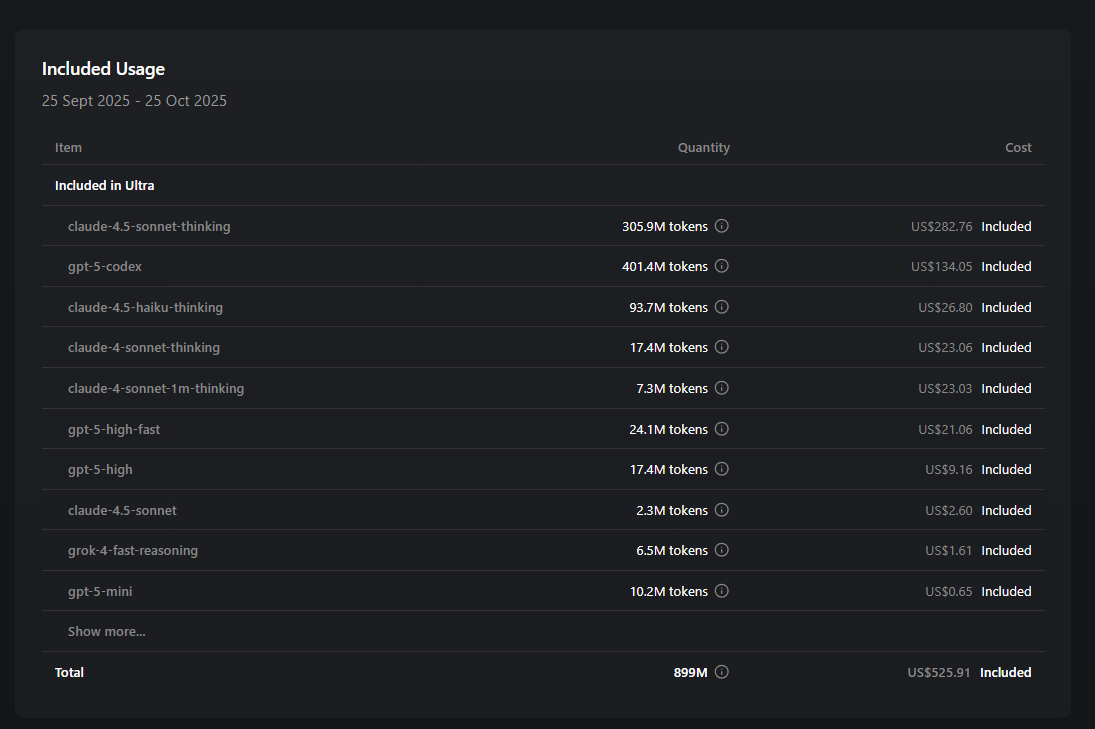
I’ve tested many models and I get a sense that models that don’t have a description tend to not adhere to rules effectively, sometimes requiring manually attachment and appears to struggle adhering to AGENTS.md, CLAUDE.md that point to “.agent”. I attached my usage as some form proof to show that I use these models extensively.
Examples of models that don’t have a description