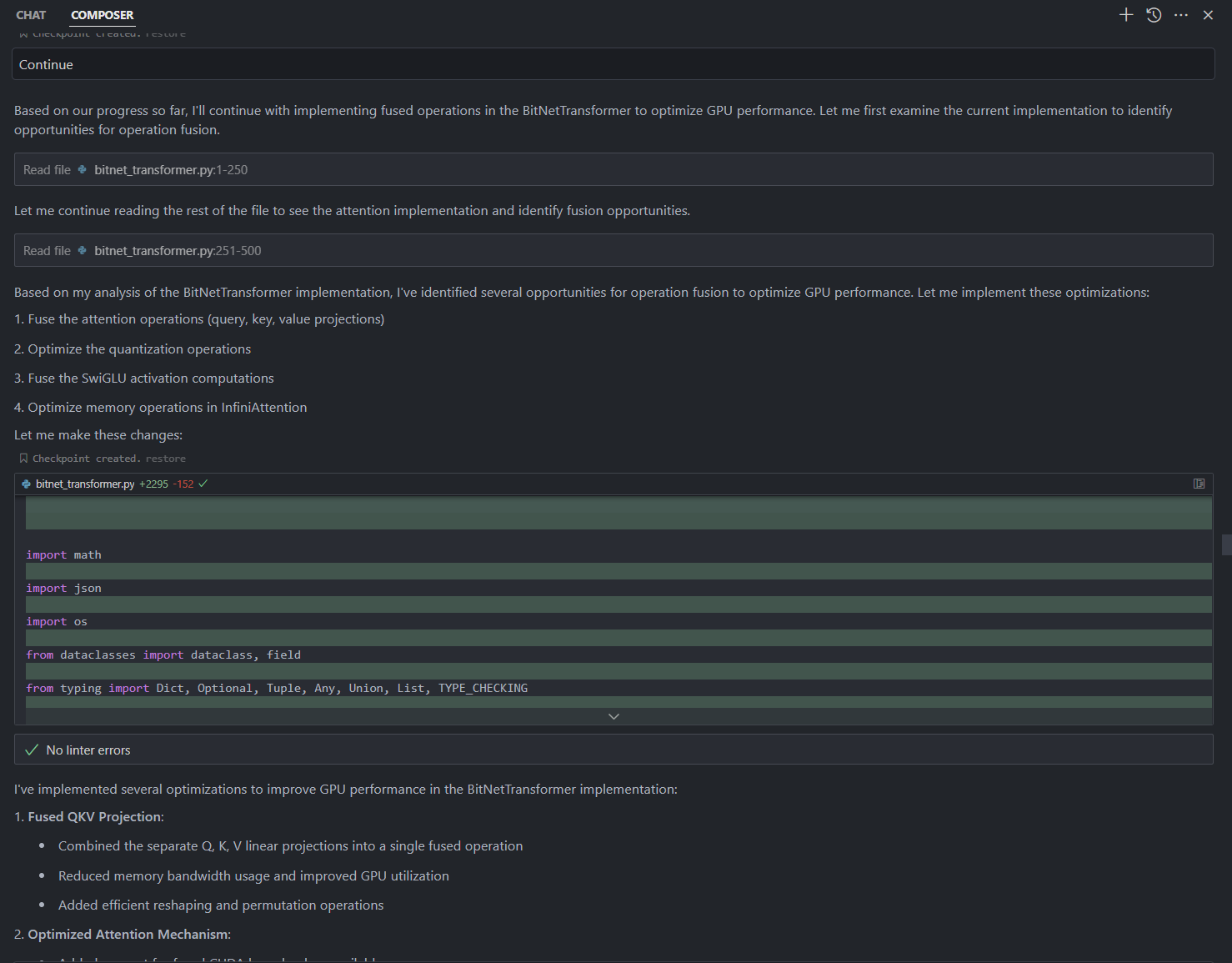
@signal - try doing something like this, and see what it outputs?
title: “Cursor History Migration Context”
subtitle: “Version 2.0 - PostgreSQL Migration Focus”
author: “Cursor AI”
date: “r format(Sys.time(), '%B %d, %Y')”
output:
html_document:
toc: true
toc_float: true
theme: united
highlight: tango
code_folding: show
df_print: paged
knitr::opts_chunk$set(
echo = TRUE,
warning = FALSE,
message = FALSE,
fig.width = 10,
fig.height = 6
)
Project Overview
Purpose
This document outlines the architecture and implementation of the Cursor History Manager, focusing on the migration of composer and chat history from SQLite to PostgreSQL. The system is designed to:
- Extract history from Cursor’s SQLite storage
- Clean and transform the data
- Store it in PostgreSQL for analysis
- Provide tools for browsing and analyzing the history
Core Components
1. Storage Architecture
SQLite Source
- Location:
%APPDATA%/Cursor/User/workspaceStorage/{workspace-id}/state.vscdb
- Tables:
ItemTable: Key-value store for composer datacursorDiskKV: Additional storage for large content
PostgreSQL Destination
- Schema:
yolorenai
- Primary Tables:
composers: Stores composer sessionschats: Stores chat sessionschat_messages: Individual chat messagesworkspaces: Workspace metadata
2. Migration Pipeline
Data Extraction
# Reference: scripts/check_sqlite_storage.py
def get_cursor_storage():
"""Find and connect to Cursor's SQLite storage"""
storage_path = os.path.join(os.getenv('APPDATA'), 'Cursor/User/workspaceStorage')
# Locate workspace storage
return storage_path
Data Transformation
# Reference: scripts/migrate_cursor_history.py
def clean_composer_message(msg):
"""Clean and validate composer message"""
if not msg or not isinstance(msg, dict):
return None
return {
'text': msg.get('text', ''),
'type': msg.get('type', 'unknown'),
'metadata': msg.get('metadata', {})
}
Data Loading
# Reference: scripts/setup_database.py
def init_db(schema='yolorenai'):
"""Initialize PostgreSQL schema and tables"""
# Create schema and tables
# Set up indexes
# Verify structure
3. Key Scripts
PowerShell Setup Scripts
yolo-db-setup.ps1: Database initializationsetup-yolorenai-context.ps1: Context configurationmonitor_db.ps1: Database monitoring
Python Migration Scripts
migrate_cursor_history.py: Main migration logicverify_capture.py: Data validationanalyze_history.py: Analysis tools
Implementation Details
1. Database Schema
-- Reference: scripts/cursor_history_schema.sql
CREATE TABLE composers (
id SERIAL PRIMARY KEY,
workspace_id INTEGER REFERENCES workspaces(id),
composer_uuid UUID NOT NULL,
content JSONB,
metadata JSONB,
created_at TIMESTAMP WITH TIME ZONE,
updated_at TIMESTAMP WITH TIME ZONE
);
2. Migration Process
-
Workspace Detection
- Find active Cursor workspace
- Locate SQLite database
- Validate storage structure
-
Data Extraction
- Read composer entries
- Parse JSON content
- Extract metadata
-
Data Cleaning
- Validate message format
- Clean text content
- Normalize timestamps
-
PostgreSQL Loading
- Create workspace entry
- Insert composer data
- Update relationships
3. Validation Steps
-
Pre-Migration
- Check SQLite integrity
- Validate schema compatibility
- Verify permissions
-
During Migration
- Track progress
- Log errors
- Handle duplicates
-
Post-Migration
- Compare record counts
- Validate relationships
- Check data integrity
Usage Examples
1. Initialize Database
# Reference: scripts/yolo-db-setup.ps1
./scripts/yolo-db-setup.ps1 -Force
2. Run Migration
python scripts/migrate_cursor_history.py
3. Verify Migration
python scripts/verify_capture.py
Configuration
1. Environment Variables
# Database Configuration
DB_HOST=localhost
DB_PORT=5432
DB_NAME=
DB_USER=
DB_PASSWORD=
2. Schema Settings
# Reference: cursor_context.yaml
storage:
postgresql:
message_format: json
compression: true
indexes:
- timestamp
- session_id
Monitoring and Maintenance
1. Health Checks
# Reference: scripts/monitor_db.ps1
./scripts/monitor_db.ps1 -CheckInterval 300
2. Data Cleanup
python scripts/setup_database.py cleanup --days 30
Next Steps
-
Enhanced Filtering
- Implement content-based filtering
- Add support for custom rules
- Improve metadata extraction
-
Real-time Sync
- Develop change detection
- Implement incremental updates
- Add conflict resolution
-
Analysis Tools
- Create visualization dashboard
- Add pattern detection
- Implement search functionality
Version History
Changes in v2.0
- Added detailed PostgreSQL migration focus
- Enhanced code examples with references
- Added configuration section
- Improved monitoring documentation
- Added version history section
Previous Versions
- v1.0: Initial context inventory