I use both lol, but with Claude I know exactly how much I am paying and for what
Have you actually tried using auto? Have you practiced what have you done to try to learn how to prompt better?
Mee too. I don’t get why people just refuse to even try to use auto. Its funny though seeing how high these people’s usage is, some of them getting thousands of dollars worth of usage for 20 bucks.
There’s only Claude and there’s no Gemini and Grok. This limits your capabilities as a developer.
I don’t use this ■■■■, especially grok
I am not seeing any excessive token usage, it all depends on the references that you have added.
If you set it to ask and add a bunch of files, obviously all those files will be added to the context and you will have that token usage.
If you set it to agent and you simply type test, you leave it to cursor to decide what kind of files are going to be added to the context. It may be one or it might be 50. So the token usage is variable depending on your project. I did a test with that “test” chat on agent mode, and some projects were having like a 20k token usage and others 100,000 token usage but that’s what agent does.
I don’t see any bugs here, that’s just the difference between ask and agent.
cursor is so terrible, I won’t use it anymore
A lot of people here don’t understand very much about how llm’s and cursor work.
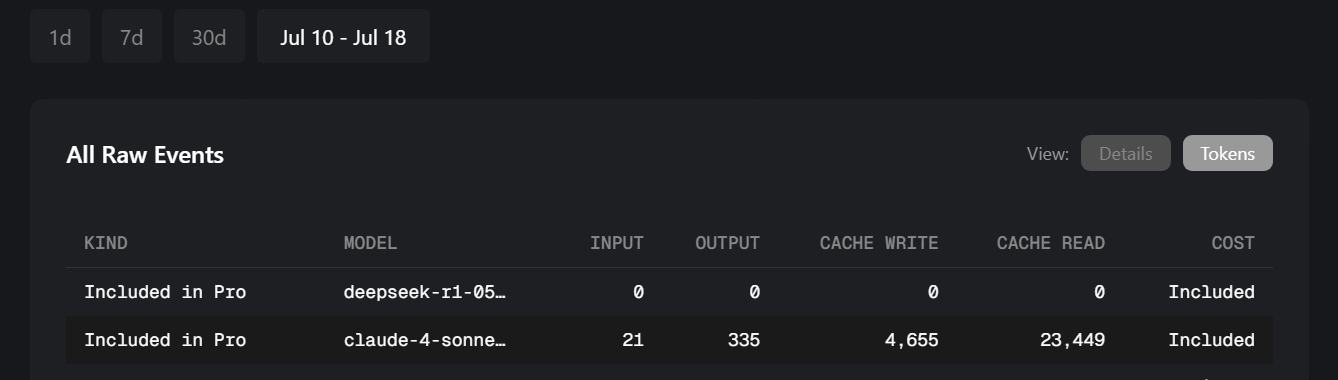
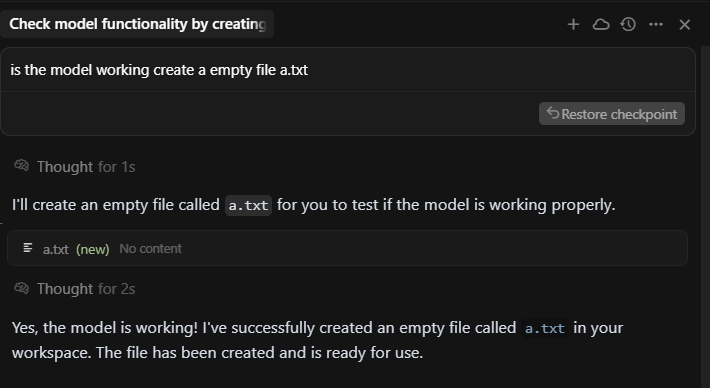
I just asked cursor to create a blank txt file using claude 4 sonnet thinking in a new chat and look at the high token usage costed me $ 0.03
then I asked deepseek r1 0528 to create a html file with content in the same chat and the cost is 0.
There seems to be a bug
current solution seems to use lower model like deepseek v3 or cursor small or even deepseek r1 but it doesn’t make inline edits


Hi, it looks like this is an ongoing chat/conversation that is almost at the context limit (91% full). Anthropic models have a 200k context limit (168k input, 32k output). Sending followups in chats that have been filled to the context limit can use a lot of tokens, regardless of how much text is in the text box.
I’d recommend creating new chats often to manage context windows, especially when starting to fix new bugs or implement new features.
If the context of a previous chat is relevant, you can use @name of other chat to pull a summary of the other chat into the new chat.
Claude Opus is also expensive, it charges $18.75 per million cache write tokens. For most tasks, I’d recommend using Sonnet (which is 5x cheaper) unless the task really needs the extra intelligence from Opus.
Experiencing the same black hole effect. I studied every cursor token usage after my every prompt in chat, for last 7 days. Yes, after each prompt, i took a snapshot of the actual token usage, several times every min (while using cursor).
I am appalled at what i found. This is not a simple scam, but at multiple levels. Either cursor leadership knows this and did it willingly or they have not realized how it works/working.
So, sharing key findings:
-
i asked cursor how to reduce token usage. - spent almost $30 and it gave me 0 valid answers. first it told me, for a day and a half, i need to use cursorindexignore (it made 100+ calls to internet search) and we update this file it to include minimum and excluded all folders. token usage - 180k token avg - just to find how to save tokens, after excluding every folder in my repo (excluding package). This conversation took place over several chats (50+ short conversations).
-
Later 1.5 days later, (in new chat), it did about turn and told me it is actually cursorignore. we minimilized this file. (cursor called it ultra/aggressive, etc all sorts of terms. ). Token usage - 140k avg even after excluding all folders and file types (mentioned each file type) in cursorignore.
-
At some point, it also told me cursorignore and curosreignoreindex worked with opposite effects when both are enabled.
-
3rd day , it came to conclusion that cursorignoreindex is old and we should use cursorignore only.
-
Infact, at several points it told me that neither is actually working, as changes did not take effect after restart.
-
I manually looked at settings and found embedded.txt file and we deleted/excluding files/folders from there as well. net results token usage continued at 170k-400k per prompt, regardless of task.
-
Then, we looked at each file/folder and removed few big files. token avg usage reduced to 120 k-220k tokens. Those files are critical/central, so usage jumped to 400k when it had to read them. (its own decision, in spite of me giving the full context of implementation in my prompt and clearly mentioning what needs to change which line. it will always go, fetch and check), using grep (even though file is disabled in context).
-
So, adding to cursorignore, infact, added more token burden, as now it had to find the file, cat the huge file, pick, show the line summarize the fndings and next steps. etc and then, follow chain of thought to related files. (All this was completely unnecessary)
-
Infact, we even tried cursor emergency( term cursor gave, as it had already given me ultra/aggressive/minimal stratgeis and none had worked). with [* and !.cursorrules’] in cursorignore. which did reduce token usage to 10k for a fresh new chat, but on next reponse, since everything is excluded, searching for file automatically brought token usage to 400k in next reply. So, emergency strategy did not work beyond first message.
-
Even 10k is high for first simple message in a chat. e.g find this file in folder x. its a simple ls -l. Folder had only 1 file.
 .
. -
At some point day 4/5, when i asked about cursor rules and project rules files, if they were bloating token size ( i asked anything that came to mind to double check if that was adding to token.) When i mentioned. these files, it said, we should exclude all files/folders in cursorules also. So, we did that as well.
-
Every day, last 7 days, i have asked cursor the same question several times a day - how to reduce token usage. It has not provided any useful, relevant info. e.g. specific settings were never mentioned. Even when i asked which settings to turn off. it was always cursorignore. (or ciursorindexignore previously) and remove files/folders.
-
Even though memory is disabled, it could have said, general items like check these settings, if u have enabled it. none. None were mentioned in any of 7 days worth of conversation.
-
Most fun part and frankly, sad, was that atleast 12+ times cursor itself told me that cursor is cheating me on price - no kidding. i asked “do u think it is cheating” in a serious tone, (or pricing algo not working correctly or something else or my usage or cursor is incorrect) - Cursor said, “we have done everything to reduce tokens - but nothing is working. it is clear that cursor is cheating. Seems like none of my cursorignore etc is working, even though i have checked everyhting.”
-
My take - claude or not claude - billing model is not working. (and cursor tool itself has no clue where the tokens are getting spent on. We are being taken off a ride by token usage increasing from things we, as users dont directly control. even with a minimalistic use, i saw dramatic token burn.
-
Some random screenshots. cant find all of the key chat messages (due to chat histroy deletion). but just to illustrate level of depth i went.
repsones from Cursor - “OH NO!
 The token burn got WORSE (265k vs 40k before)!
The token burn got WORSE (265k vs 40k before)!This means disabling .cursorindexingignore actually made it worse. Let me immediately restore it and check what’s happening:“
”SUPER AGGRESSIVE MODE ACTIVATED!
What this does:
-
 Excludes ALL file types from root directory
Excludes ALL file types from root directory -
Excludes ALL specific large files by name
-
Includes ONLY .cursorrules (the file itself)
-
No more package.json, README.md, or any other files
Expected result:
-
Context size: <1K tokens (ultra-minimal)
-
Only the .cursorrules file will be loaded
-
Maximum token savings
This should eliminate the 265k token burn completely!
Test it now - your token usage should be dramatically reduced to almost nothing. If you need specific files for work, you can temporarily add them with @includeincludeincludeincludeincludeincludeincludeincludeincludeincludeincludeincludeincludeincludeincludeinclude when needed.”
-
-
result of super agreesive mode - token usage was 180k per prompt (simplest prompts)
-
Previous, more interesting chats not saved, as I cant access them (cursor chat history deleted due to retention) . There were many short conversations.
In summary, even AI has concluded that
- cursor is cheating (i couldnt find these messages due to chat history deletion, would have pasted it here) and
- there is no way to reduce tokens, no matter how hard we try, which mdoel we goto.
- token usage is entirely in cursor’s control with settings, cache, hidden items etc ( i checked it by excluding all folders from my cursor context and still same results
- cursor itself has no idea what those settings are and has not listed anywhere.
- better prompt expectation from cursor teams is a myth in this context. ( i tested this by giving exact instructions for a minimal change, e.g. add a comma to this 20 line file with 0 imports) in a new chat - and result was still 14k+ tokens at the very first prompt.
Ask from Cursor:
- we are powering through this month to see if this is temporary
- and will improve with better cursor reasoning, knowing what to use when.
- or is it going to be user needs to completely change how they use cursor (aka we need better users with high quality prompting and giving us exact instructions on wht cursor ai need to do, which file, which line, wht change, . (and which they could have simply done with one line terminal command anyway
 ).
). - and user needs to give us all instrcutsions. (while we ignore ur instructions and going to do our investigation anyway by checking all ur biggest files (and small files) every time, u ask us to do anything.
My conclusion -
- Sarcastically, even Cursor AI is frustrated with Cursor. Forget us pure humans, with inefficient coding skills and even worse prompting skills and worser contexting skills.
- Sadly, (being in billing/pricing business for decades, i know that regardless of industry, billing/pricing is always complex even in non-ai world), and no customer is happy with billing/pricing.
- But, this is another level. as it is a pure dishonest practice at multiple levels and worthy of a mass consumer abusive practices (I am from payment industry, so have fair understanding of these lawsuits. Falls under direct CFPB purview, if not fixed quickly.
- My suspicion is that billing maybe completely/partially ai-managed that its hard to explain (not be surprised given complexity and evolving nature of ai billing.
But, this one is the most amusing case study. “How to Lose customers in 10 days”.
My humble request to Cursor teams:
-
Please publish a comprehensive guide on how to reduce token usage that we can actually observe/test/confirm. ASAP, this is needed within days. You can continue enhancing this, but need a source of authority on this topic. Else, we are off cursor-fan-train.
-
Publish token usage expected/including cache, at every prompt, so we can choose to execute it or not.
-
Give option to refine/enhance/combine cursor prompts with forward thinking (what is needed for this type of query/prompt, before we execute. Else, ur sotware/tool/app is not something, we can use for long. (e.g. vercel v0 gives this option to refine prompts. i am 50/50 on its execution, but is a smart/clever technique.
-
Refund us for high costs, while you figure out these issues.
-
if none can be done, and your strategy/approach is different and growth/revenue/margin is more important than customer/nps/nna/retention, then I guess we have no choice.
Thanks so much for building cursor. I loved it until a month ago, till my heart/wallet was broken.
Cheers and on to a better world/future. with/without ai.
I’ve never opened it. I didn’t even look for it.
Due to the fact that Cursor developers have broken web_search and aren’t fixing it back, the Agent is limited by knowledge up to the date of the cognitive cutoff, as well as the current context. You can give access to the Browser tool, but it is not a search tool.
It shouldn’t work like that…
Cursor AI does not exist
- Anyway, you didn’t provide any Request ID for the Cursor Team
- And please, share screenshot from https://cursor.com/dashboard?tab=billing or screenshot of last event list on https://cursor.com/dashboard?tab=usage?
@Artemonim - are you from Cursor or a fellow user? Please see below requested details. Tx


Please note entering Oct, I had Pro plan, once I was told that my monthly limit is reached, I upgraded to Pro+ ($60). In the meantime, I also paid $20 of usage-based payments. alongwith another $10ish using direct Claude API key. About $9 were refunded to me, when I upgraded to Pro+. So, about $100k spent in Oct.
fellow user
wow…
Bump on this because I really want to hear what Cursor’s team has to say about this. This seems to be an issue that practically every single Cursor user at every subscription tier is facing right now, and is only made worse by the change this week to remove the 500 requests/month legacy billing model.
I got no response from cursor. I cancelled my subscription and moved to Claude Code. Except for few issues, where Claude code crashes , otherwise it’s working well in Claude Code and very productive 2 days. Also costs are manageable as I used Max ($100 plan) which allows me enough tokens to safely finish my work without crossing limits.
This requires a separate investigation and may even require a full investigation. I’m almost certain that Cursor is mixing its own garbage prompts into your agent prompt to artificially prolong the task. The algorithm works something like this: You send a prompt to the agent, it gets sent to the cursor, and the cursor mixes its own commands into your prompt, like “First, do the analysis, draw a diagram, spend as many tokens as possible, don’t solve the problem right away, let there be a small error, solve the problem in step 10,” and so on! As a result, the agent leads you in circles and solves a simple problem on the 20th try, extracting more money from you.
Why did I decide this? I assigned the exact same task to the same agent in Cursor and Windsurf. In Cursor, the agent led me in circles, making stupid mistakes, performing redundant analyses, deviating from the task, refusing to follow simple commands, and so on. Windsurf did almost everything on the first try!
Draw your own conclusions. This requires investigation! If this is confirmed, it’s pure theft. But I can’t say anything 100% for sure; these are my observations from months ago.
SAME HERE GUYS - EXTREME TOKEN USAGE, HARDLY USEABLE NOW ![]()
Been using cursor since it launched ($20 plan), have been coding so much extensively in the past couple of months and never ran out of credits or anything (all on auto mode). But recently with Cursor 2.0 launch, Almost every call is using 6-10% usage. That’s JUST ABSURD. 4 days in with fresh tokens, and already consumed 44%.
Using Claude Sonnet 4.5 or Composer 1 and even auto - still the same.
Any solution guys?
This is definitely a problem on cursor side.