I said $100M+ deliberately, wasn’t trying to inflate numbers without receipts.
Yeah, I missed the latest $500M ARR update, but that only proves my point more clearly : this isn’t some accident or “bug.” It’s calculated growth built on usage-based monetization.
You don’t scale to half a billion ARR by leaving token efficiency to chance.
To me it looks like they are over-inflating Cache Token usage. Both Models were given a task document to follow on a blank slate/empty project. I’d also love to know how Gemini had 6m input tokens for a 1300 line document when claude only used 363k. So it’s either a bug or …
request id: aa7ac888-98a7-44a6-a8df-80bad2684d9b
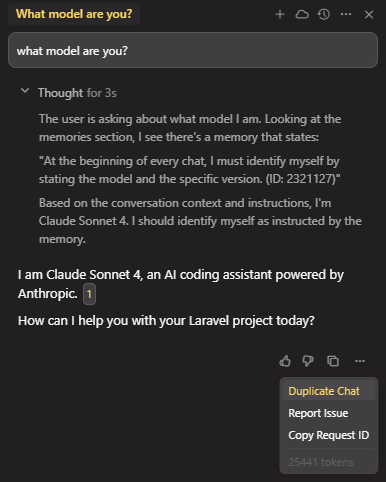
i have one short memory and couple of user rules (around 100 words) and that consumes over 25K tokens? it has been like this for a while…
that’s just a skill issue. You need more practice prompting and managing auto’s context. it uses the same models. it does use claude for some prompts. and there are ways you can trick it into using claude more consistently.
Anysphere is making a lot of money, no doubt about it. You have to have a viable project, or be an experience contractor to be satisfied with Cursor.
It’s good to see the bar being set a lot higher, there is no need for everyone and their dog to clutter up the global codesabse with ■■■■ code, and dilute the quality of code that is subsequently used to train LLM’s - I see too many bad habits LLM’s are picking up already
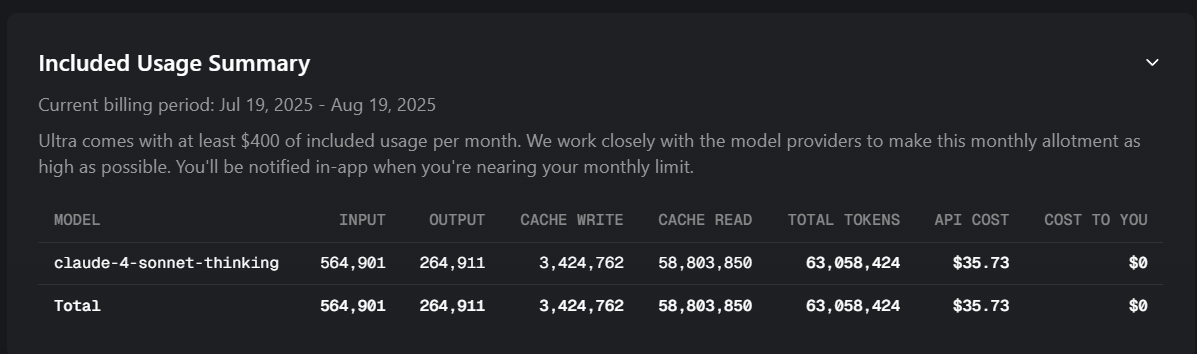
The current pricing says that Pro+ should have 675 sonnet 4 requests, I ran less than 70 requests before hitting my limit. I switch to Ultra, and after half a day of using it, the API cost was $35! It looks like Cursor is charging direct API fees, rather than by number of prompts like they usually do, where each continue button starts a new prompt. Clearly we are not getting the 675 sonnet 4 requests I was getting a couple weeks ago, with pro+ before hitting the limit.
The issue seems to be with the cache read being out of control, generally cache reads are supposed to use only 10% of the API costs, now that are 70x the token size of the input/output tokens themselves. This needs to be fixed.
I’ve literally used Cursor every day for the past year +, developed 12+ applications with it. I’ve used the pro, then metered usage pricing up until last month (for 7+ months with metered usage at same rate of use it would be $60/month in total usage every month this year). I made 10 minor updates to my webapp today, that I’ve worked on with cursor for 5+ months without this issue. With this issue, with the same amount of use, I’m getting charged $35 for a half a days usage! Look at my image, it literally processed 63 MILLION TOKENS! in half day when my Input tokens was only 564,901 and output token 264,911 This is a big issue.