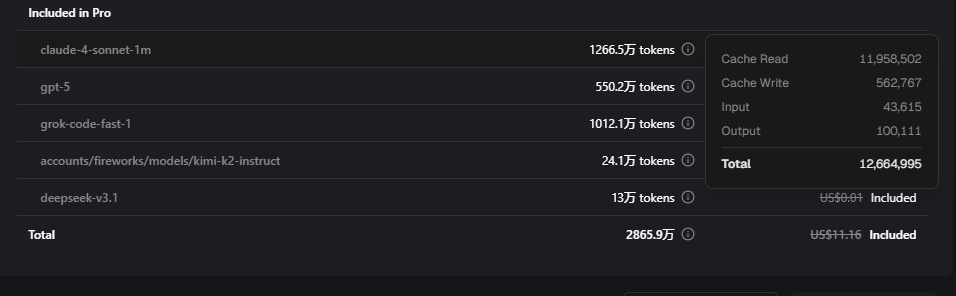

I cannot accept the number of tokens read from the cache. How can I reduce their number?
Why would you want to reduce cache reads? It doesn’t make output worse, it just makes it cheaper.
hi @tiantianaixuexi there are a few ways to reduce cache reads.
As @Ra.in says they are important to reduce your cost at no quality loss.
Why do cache reads happen?
- When you submit a request for Agent it gets processed at AI providers into tokens and then you receive a response from AI. Those tokens are cached for next replies to reduce cost by 90%.
- Each AI tool call and user request is an API request to AI provider. As now only the new part of the chat or AI tool call need to be processed you receive 90% token cost for cached tokens. AI still processes whole context to create a response.
- Not using cache would mean that the same amount of tokens would cost full input price at 9x more than the cached token cost.
When is it an issue?
- In case a chat thread gets too long it may have a large context used and therefore consume a lot of tokens accumulated.
- Possible effect is also that AI gets confused by too much conflicting information in context when chat gets too long.
Solution:
- Keep each chat focused on single task.
- Use simpler models for simpler tasks.
- Use large context like Sonnet 4 1M only if the regular Sonnet 4 model can not fit the required context in 200k tokens. Note that tokens over 200k cost 2x as much as regular context until 200k tokens.
Additional details about token usage:
I fully agree that the ratio of ‘cache read’ to ‘productive’ (input/output) tokens has an unacceptable balance.
Look, I understand the rationale for cache tokens.
But for me, over the past 2 months, I can confirm that the share of cache read tokens is usually between 96-99%.
So even if the tokens were to reduce cost by “on average 90%”, it’s still a bad deal! I’d rather pay 10x as many tokens for my production than 50-100x the tokens by providing more context.
And on top: The “90% cost reduction” is a vague claim that I have read at several places, but never seen any actual math behind it.
So my bottom line: Cursor is so massively inflating the I/O by creating context that I have a hard time believing this is justified. I personally believe that I tend to write good prompts (e.g., specifically providing some info on what packages/modules I am referring to, what they are intended to do, where I see a challenge, and ask in turn for refactoring of 2-3 specific methods). I believe I can get along with WAY less context. (Obviously, if you just prompt: “Refactor this entire repo for better performance”, then Cursor has not chance but to go wild… but I think most engineers would feel that that’s not a good prompt).
I cannot confirm this. I often start new chats - particularly every morning.
Nevertheless, even the first prompts of the day show that crazy imbalance. Today:
- First prompt of the day: 108k tokens, 91k context (84%)
- Second prompt: 104k tokens, 96k context (93%)
- Third prompt: 120k tokens, 115k context (96%)
And some have even higher ratios.
Again, if interpreting context costs 20x the number of ‘production’ tokens, I’d rather straight-out have 10x the cost. At least production prompts is something I can control.
There must surely a definitive way how a user can TELL cursor to use less tokens for context?!
It's only been 5 days and my monthly subscription has already been used up. This is too much.
hi @KingOtto sure your use case may not be same as others. I did really not catch what you meant with 20x or 10x.
You can sure instruct AI to be terse and use less verbal output, also you can choose models that are non-thinking or in case of GPT-5 the -low variant which is low thinking.
But AI may still need to read code and do its tasks so that part can not be reduced easily.
@tiantianaixuexi have you had a look at the link i posted above? It gives tips how to reduce token usage.