Yes its conjecture, but I’ve been wondering the same thing. I always wondered how they paid for all the free user tiers as well. Pricing for Amazon Kiro.dev have been floating around which is Pro ($19/mo for 1k agent interactions), Pro+ ($39/mo for 3k). Not sure if its correct, but that would be another company offering Claude 4 Sonnet at the prices and better than the usage rates we are used to.
If Cursor isn’t going to properly fix Pro and Pro+ accounts that used to last all month that are draining in 3 and 7 days respectively. I see a mass exodus, very few people are going to be able to pay thousands of dollars a month to use Cursor.
This is incredibly unfortunate, if I had to choose an IDE it would be Cursor and i would pay the $200/mo Ultra subscription all year long to use Cursor with the same usage rates as before that would last all month.
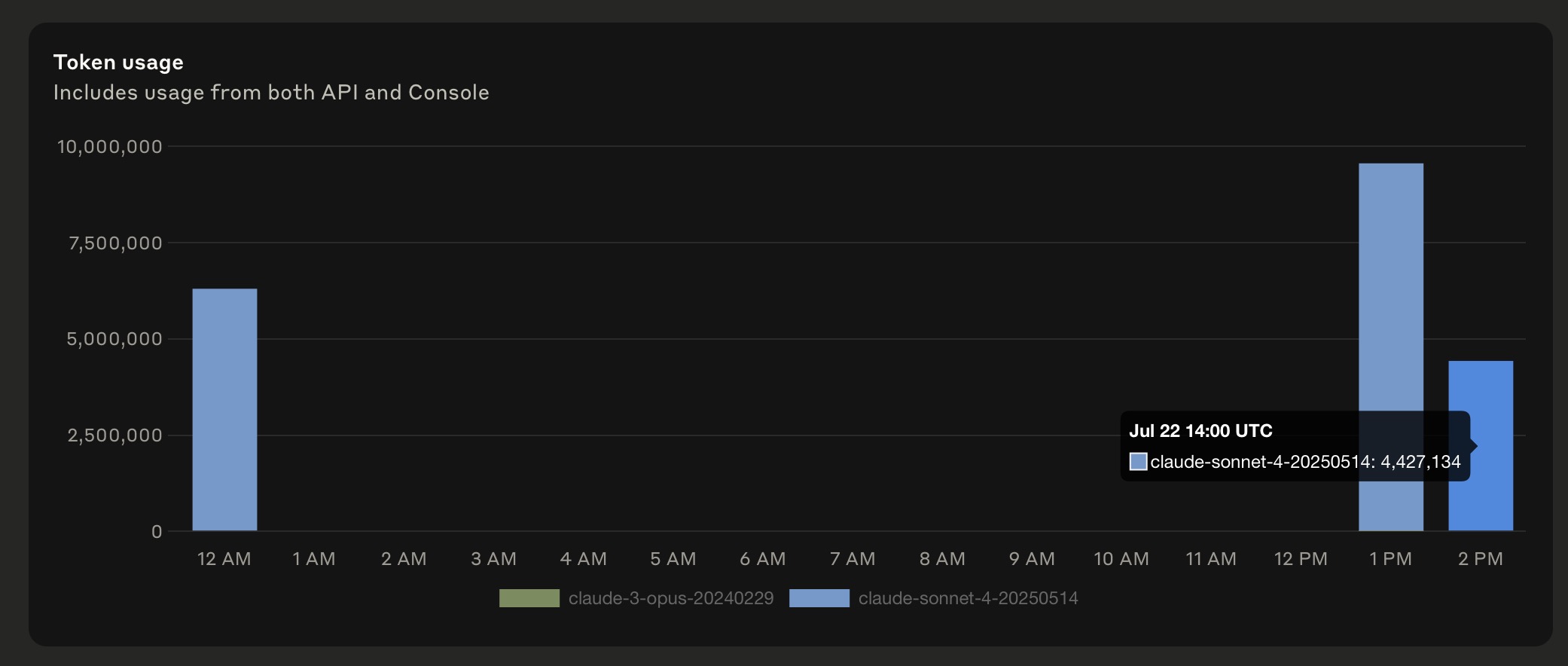
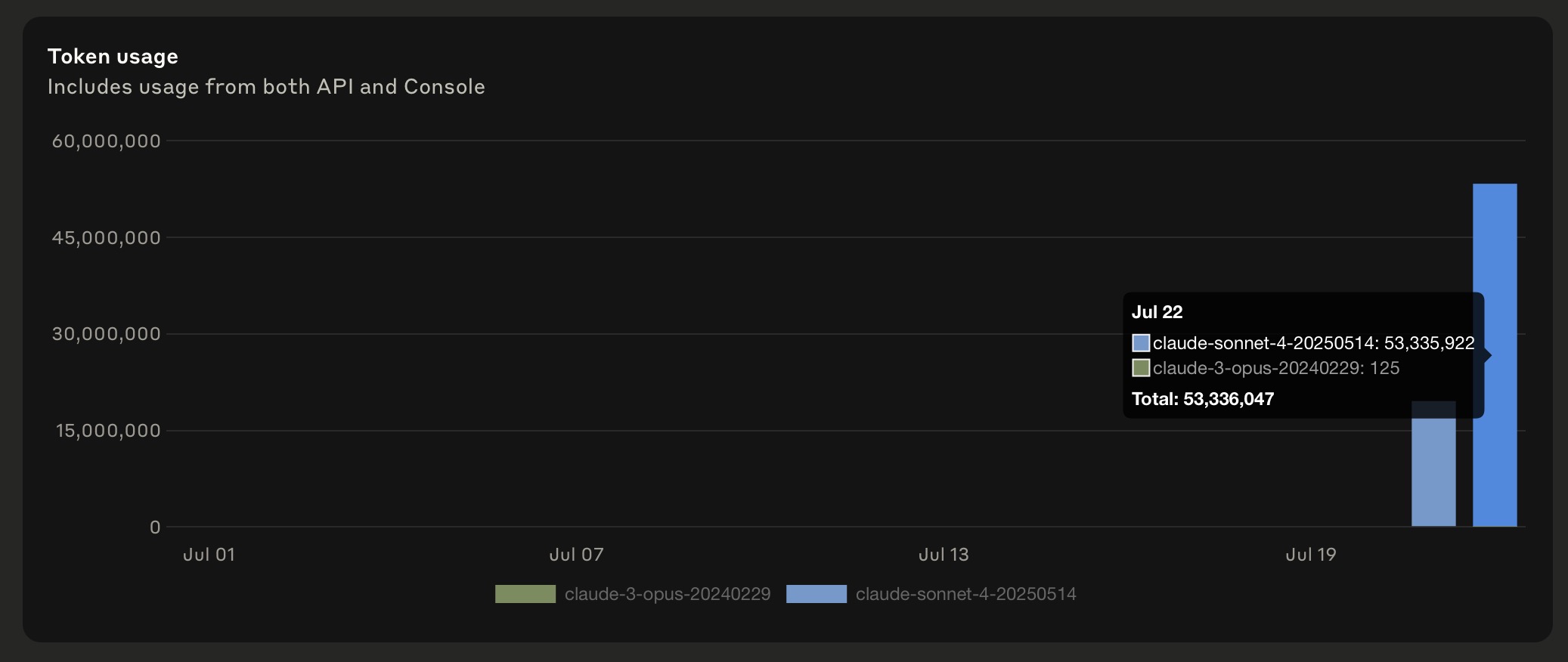
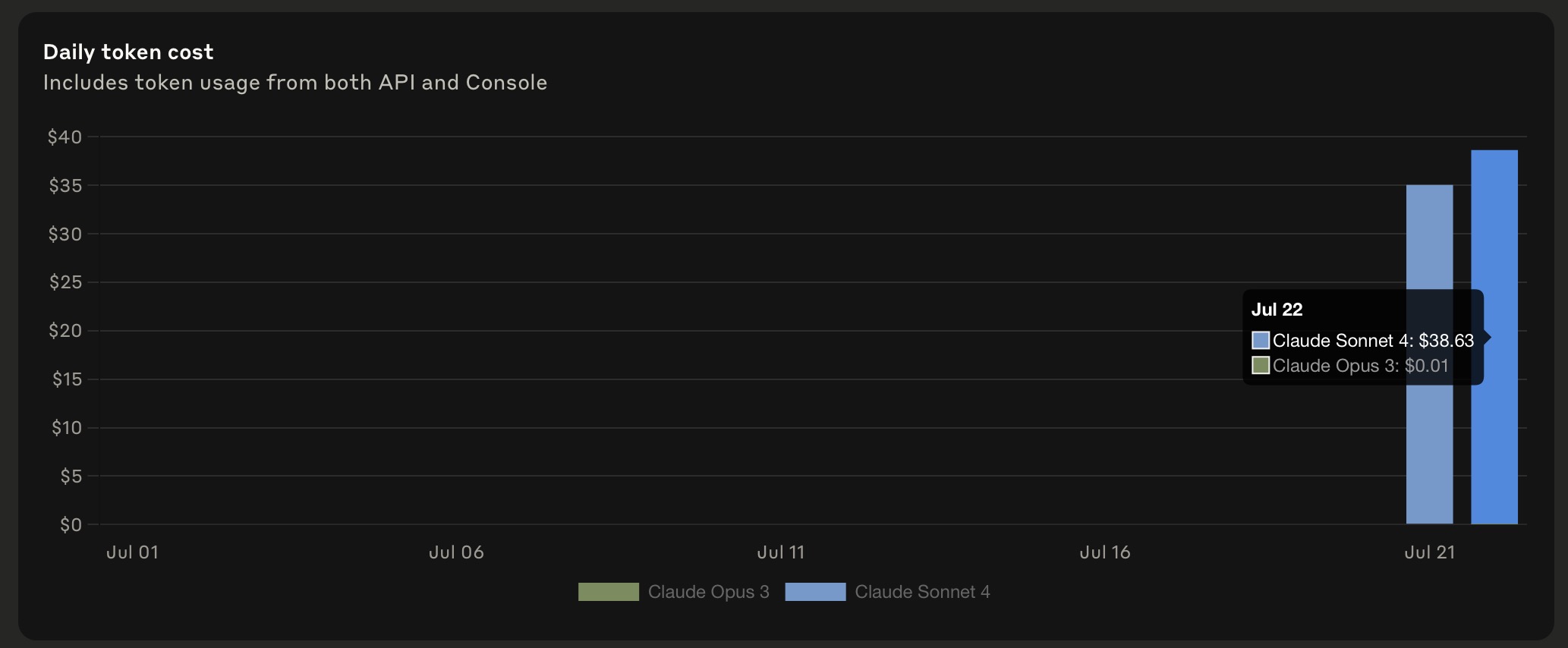
The Cache Read bug is getting worse, since the 2 Billion Token screenshot above. People are reporting that even when there is 0 cache write, the cache read was still 43 million tokens!! What cache is being read, if there was no cache write?
This is from Anthropic’s console.
Pure Cursor’s usage is the last hour I think, if both hours then it’s even crazier difference because it all costed me $7.97
@danperks@Zackh1998 We are still waiting on your answers to these 3 simple questions. Please provide clarity to get to the bottom of this:
What technical changes have caused this 10x increase in token consumption? Users are performing the same development work on the same projects with identical context.
Why is there such a significant discrepancy between advertised request limits and actual usage?
Pro+ advertises 675 requests → I received 60-70 when it used to last a month with left over tokens
Pro advertises 225 requests → Users report depletion in 2-3 days who used to get a months usage
Can you provide an option to revert to the previous settings that didn’t cause excessive cache read consumption & 10x drain?
Technically something is causing this 10x increase of token usage for the same work on the same dev project with the same context. Can’t you offer the options to turn back on the previous settings that didn’t cause a 10x cache read drain? I really hope this isn’t a bait and switch to get users to pay full API fees, rather than usage rates that matched the amount of requests our subscriptions provide listed at Cursor – Models & Pricing .
Expected usage within limits
Expected usage within limits for the median user per month:
I think Zackh1998’s post perfectly corroborates my previous findings. As he said:
But the system prompt encourages the model to call tools to understand all the details, encourages the model to explore multiple implementation methods and multiple search keywords, and forces the model to use different keywords for multiple searches, requires the model to break down the task into subqueries multiple times, and requires the model to use tools as much as possible. If it’s a complex project, such prompts will inevitably lead to an explosive growth in token usage. As he said:
But I think the situation might be even worse. In a slightly more complex project, to understand every detail of a particular file, it might even be necessary to read half of the project’s files. This could cause the initial 20,000 tokens of context added by the user to expand to an incomprehensible size, far more than just 30,000. Then, because the system encourages or even forces the model to make more tool calls, this massive context is repeatedly included, ultimately leading to enormous token consumption.
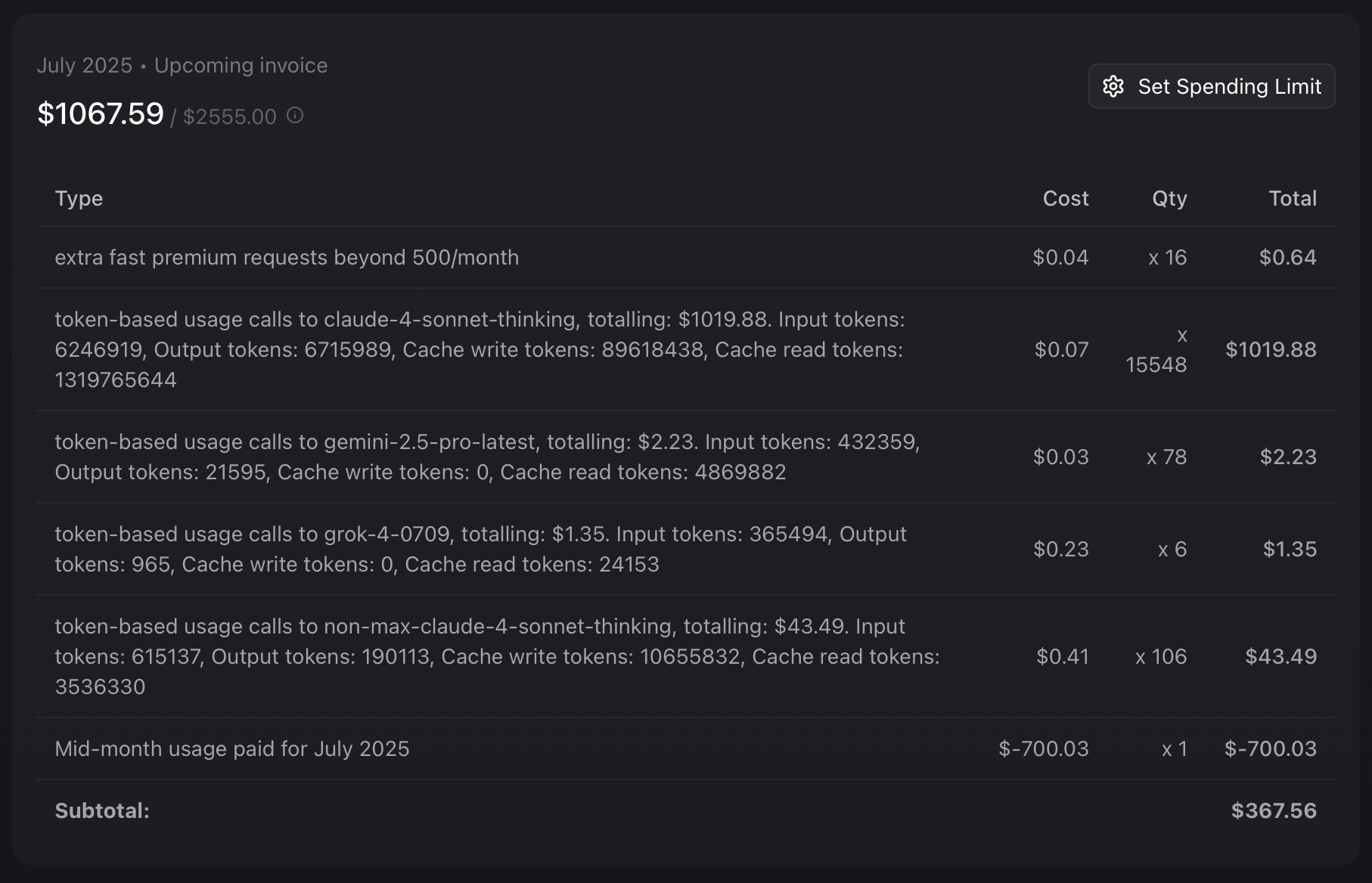
Ps: Zackh1998’s post merely explains that the ratio of input tokens to cached tokens is normal (1:9), but avoids the most important question: why such massive token usage occurred. According to his post, cached reads can actually be understood as inexpensive input tokens. Excluding the price factor, cached reads are essentially input. That is, for the friend who consumed 2 billion cached read tokens, the actual input for this request is over 2 billion plus 6.6 million, while only outputting 10 million tokens. The input-output ratio reaches 200:1, which is far too absurd.
Additionally, I have another question. Someone mentioned in a post that their pro plan ran out of tokens after using $86 worth. I remember a developer once replied to a friend in the forum saying that he had used more than $150 worth of tokens. But why did my Pro plan run out after spending $64. I want to know what caused such a significant discrepancy. Let’s set aside whether the pricing is reasonable for now; at least every user should be treated fairly, right?
Cursor is a hot mess at the moment, hope they sort out their pricing and token overage problems.
Their investors must be mighty upset at the team for blowing this
Pro comes with at least $20 of included usage per month. We work closely with the model providers to make this monthly allotment as high as possible. You’ll be notified in-app when you’re nearing your monthly limit.
I’ve been waiting 2 days for answers to my basic questions about this. They have answered other questions and skipped over it for me so far. Hoping they address it.
Hey, you can see my response to the high cache read query here:
To summarise, your conversation is re-read by the LLM on every tool call - this is the same with all tools that have the same agentic workflow, not just Cursor - which accounts for the high read token throughput.
Thanks for the response, but it still doesn’t answer my main questions. There are hundreds of people actively expressing this same issue, and likely tens of thousands + who are experiencing it.
Why is there such a significant discrepancy between advertised request limits and actual usage, specifically clients whose accounts lasted all month and now last a fraction of that with same usage on same projects? These are direct before/after changes of 10x token drain. Why did the previous version of cursor not do that, and why can’t we have the option
Pro+ advertises 675 requests → I received 60-70 before running out of credits in 7 days on a pro+ that lasted me all month with left over credits on the same project/tasks. I reran previous tasks, with backups of my code base that had correct usage rates before that are now showing the 10x drain.
Pro advertises 225 requests → Users report depletion in 2-3 days who used to get a months usage
Can you provide an option to revert to the previous settings that didn’t cause excessive cache read consumption & 10x drain? Michael Truell said legacy users could opt to switch back to 500 requests a month on June 16th 2025 (Link )
Technically something is causing this 10x increase of token usage for the same work on the same dev project with the same context. People who used to get 100% usage rates are getting 10% of what they were getting compared to the provided median request usage expectations listed at Cursor – Models & Pricing .
" ### Expected usage within limits
Expected usage within limits for the median user per month: