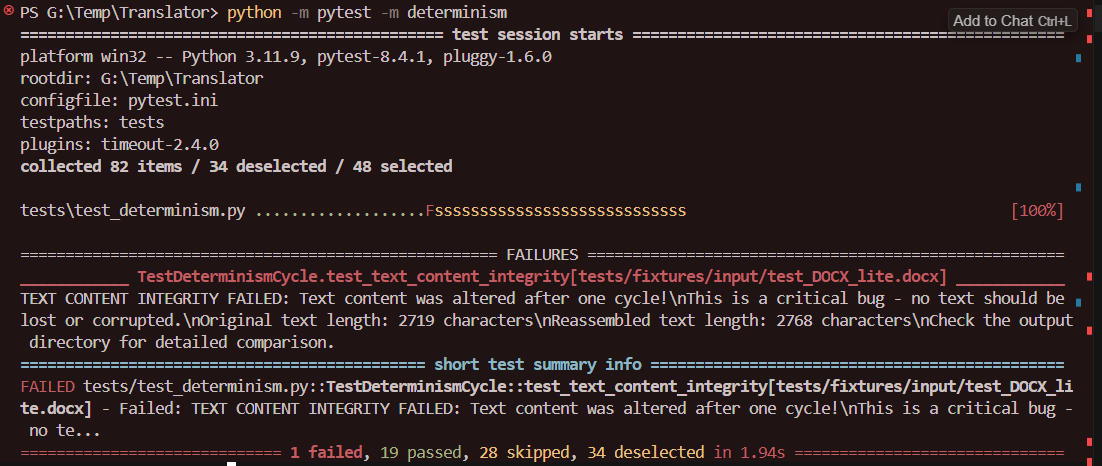
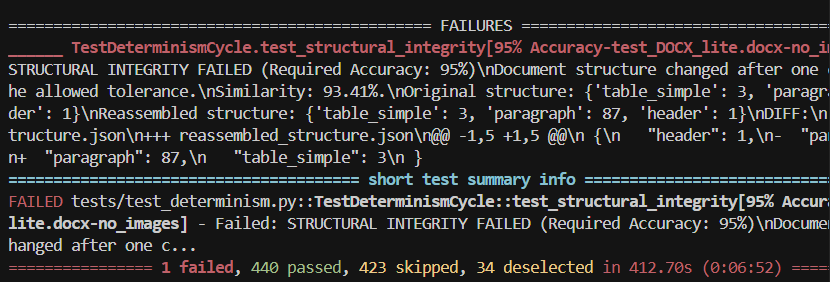
I’ve been trying to develop a CAT tool for personal use for almost a week now. I wrote an incremental integration test with 48 tasks to track progress and follow a TDD-style development workflow.
I’ve hit a wall at Task 20 — none of the available LLMs have managed to pass it so far. I’ve tried everything, both individually and in relay races: Gemini 2.5 Pro, Gemini 2.5 Pro MAX, Claude 4, Claude 4 MAX, o4-mini, o3, o3-pro (Manual mode one-time situation analysis), and Auto. Auto and o4-mini break previously working logic right out of the gate. o3 messes up the terminal with commands I don’t even recognize.
The project is private, so I can’t share anything more detailed, but I’ll be over the moon if my magic wand gets released tomorrow night.
Hey, as with every major model release, we are working to improve Grok 4 currently, both on available capacity from xAI and on it’s stability within Cursor. Each model requires some custom tuning of it’s system prompt to ensure it behaves well inside of Cursor - they very rarely can be “dropped in” and work immediately.
By the way: when models can’t correctly apply changes via edit_tool or think they can’t, is this the problem of the applying model or the LLM itself, or both?
Just over a week ago, I didn’t even know how to use tests.
Now I’m spending hours optimizing a four-layered parameterized integration test for idempotency, trying to get it to run in less than 11 minutes
(and that’s with only 47% of the test currently executing).
You complain and only complain about absolutely every LLM. Either your tasks are too complicated, or you have problems with prompt-engineering. Try using my Agent Compass. It will be interesting to see if it can help you.