The fact that you are such a new company playing games, when or name a company this tactic has ever worked out well for? None. Not renewing, not recommending.
3 Likes
Did you purposely not answer the main question, why are tasks that usually take under 5,000 tokens, taking 3-4 million tokens!!! The problem here is that we’ve tested the same prompts on other systems like windsurf using the same ai model and we get the usual < 5,000 token requests that Cursor now spends 3-4 million tokens on. This is why everyone is running out of credits, its very clear. You literally answered like 10 people and avoiding answering the main issue people are having! It’s starting to seem like your obtuse response is on purpose? That’s what a lot of people are starting to think. There is clearly a bug that is processing many times more tokens than it used to, this is why peoples credits are being used up in a week! You need to fix this or I and many other users are gone. I’ve already started using Claude Code as a result of this and it’s looking pretty good. Requests are using under 2,000 tokens that cursor is saying is 3-4 million tokens. Why would anyone ever use Cursor again, you are literally processing and charging for 800x more tokens with this bug. It’s absurd, and for you not to acknowledge it makes me seriously consider never coming back. FIX THIS ASAP!
It seems like you are mocking and making fun of the people here who are clearly showing that the tokens are way off from what should be used. Clearly this person is experiencing this exact bug where 5,000 token tasks are using 4 million tokens, yet you joke like wondering how he could have used that much API, HE DIDN’T IT’S THE BUG OVERCHARGING PEOPLE BY 800%. STOP PURPOSELY AVOIDING ADDRESSING THE ISSUE AND MAKING FUN OF PEOPLE WITH THE ISSUE.
You wrote “@Codingbotguy I’m surprised to hear you have managed to consume enough to hit our limits, although looking at your account, you have used >$2000 worth of model usage already! Thats over 15,000 requests to models (more than 1 every 2 minutes, 24/7). I’d love to hear more about your usage pattern that has got you to this point!”
Others have confirmed this:

2 Likes
You will not. You will get more, but nothing close to unlimited, especially not Opus.
They never advertized unlimited usage on all models. They only said unlimited usage in some models aka auto.
Give me a prompt to use on an empty file. Let’s see if we get the same usage. Maybe you have a bug maybe you don’t understand how cursor works. But let’s find out by us both doing the same prompt on an empty file and checking the usage.
1 Like
The current pricing says that Pro+ should have 675 sonnet 4 requests, I ran less than 70 requests before hitting my limit. I switch to Ultra, and after half a day of using it, the API cost was $35! It looks like Cursor is charging direct API fees, rather than by number of prompts like they usually do, where each continue button starts a new prompt. Clearly we are not getting the 675 sonnet 4 requests I was getting a couple weeks ago, with pro+ before hitting the limit.
The issue seems to be with the cache read being out of control, generally cache reads are supposed to use only 10% of the API costs, now that are 70x the token size of the input/output tokens themselves. This needs to be fixed.
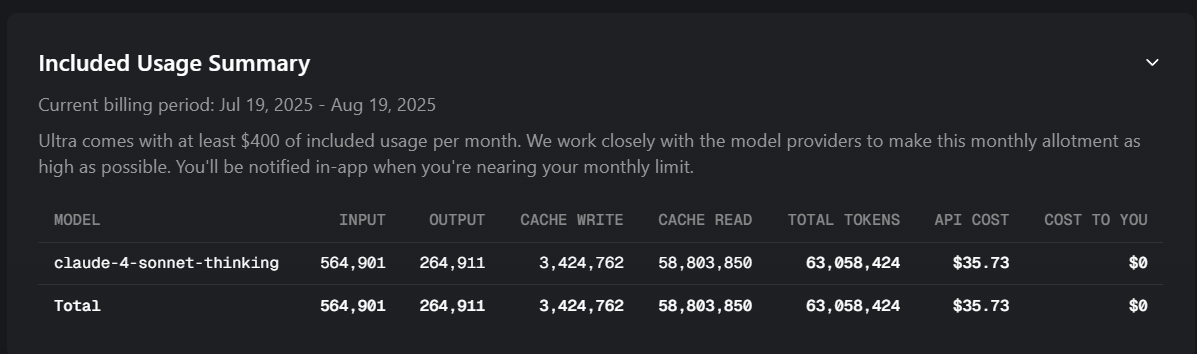
I’ve literally used Cursor every day for the past year +, developed 12+ applications with it. I’ve used the pro, then metered usage pricing up until last month (for 7+ months with metered usage at same rate of use it would be $60/month in total usage every month this year). With this issue, with the same amount of use, I’m getting charged $35 for half a days usage! Look at my image, it literally processed 63 MILLION TOKENS! in half day when my Input tokens was only 564,901 and output token 264,911 This is a big issue. I get that your simping for Cursor, but this is inexcusable!
6 Likes
I love cursor. No idea how this is defensible.
I can’t say whether or not there is a token processing bug. Some of these posts are silly though. If you don’t like the way Cursor enforces token limits then bring your own API key and pay the model providers themselves. But none of you will do that because you know the cost would be much more than a Pro, Pro+, whatever plan. The truth is you’re paying pennies on the dollar for tokens using Cursor. Anysphere are scrambling to figure out how to turn a profit. And if you’re surprised I don’t know where you have been the last 10 years. Every single SaaS has the same playbook.. operate at a loss, get people hooked, then raise prices. ![]()
4 Likes

But the limits reset every few hours for Opus! I can live with that!
[MOD - Condor - Edit: translated to en]
I use Cursor because of its excellent models like Claude-3.5 and 4, but now the usage has increased significantly compared to before. Previously, a single question cost me about $1.8, which is much more expensive than the $0.04 it used to be. Although the slow mode was at least high quality in terms of output, now the code quality from ‘auto’ mode is much worse. Maybe you could let users allocate their quota to a specific model. After the pricing changes, I feel unable to afford it, so I might have to consider other IDEs.
1 Like
I use Cursor because of its excellent models like Claude-3.5 and 4, but now the usage has increased significantly compared to before. Previously, a single question cost me about $1.8, which is much more expensive than the $0.04 it used to be. Although the slow mode was at least high quality in terms of output, now the code quality from ‘auto’ mode is much worse. Maybe you could let users allocate their quota to a specific model. After the pricing changes, I feel unable to afford it, so I might have to consider other IDEs.
1 Like
I think Auto mode is unusable. For certain tasks, I need to use a specific model, as they perform better on those tasks. When you get hit with a rate limit notice, it is hard to switch to Auto mode in the middle of a task. In Auto mode, as they say, requests are routed to different models, so there is no way to know the quality of the response.
In one case, which was trivial to fix, Auto mode got stuck in an infinite loop and started repeating tokens endlessly, something that had never happened before. Despite having clear instructions and a to-do list, Auto mode sometimes invents its own version of the task and jumps straight into editing. The list of bugs goes on…
2 Likes
I’m seriously considering deleting my account and switching to another platform if the pricing plans don’t improve and the changes aren’t handled more professionally.
2 Likes
I don’t know what to do anymore I’m burning through tokens SO FAST it is ridiculous. I can’t work with cursor anymore it is just impossible I have to stop working on my project until I find another program I can work with. I already upgraded to pro+ and even with pro+ I’m completely drained out of tokens in NO TIME. I’m kind of desperate, I hope I can set up Claude Code fast enaugh
3 Likes
You got an attitude that needs adjustment; yes monthly users can and will choose to keep or cancel their subscription. However, there are people that paid for an annual membership based on terms and conditions that have changed several times over.
You are not some oracle that sees what others don’t see; there are real people that are dealing with a constantly shifting landscape. I don’t give a ■■■■ if you think it’s silly for people to pay for an annual subscription, it is immaterial to the fact that Cursor keeps changing their usage models on people who have committed to them for a year.
Good for you that you’re so SaaS advanced that you can come to a forum like this and offer nothing but criticism, you must be a ball to work with.
8 Likes
Hey all. Just to add some clarification, there may be two things at play that may be going on here, which is likely different for each of you:
- Dashboard Bug - We recently fixed an issue with the cursor.com dashboard that was showing each tool call of a MAX request as its own individual line. This meant that, while you may have had more lines with lower token usage each, these have no been combined to show one line per request - the token usage will now be the sum of all tokens used in a MAX request, which may lead to very large numbers showing up on your chart.
- High Token Usage - With our recent pricing change, the usage of your plan is entirely dependant on your usage of the LLMs. We always guarantee you get at least the $ amount of your plan in API usage, and at the moment, you get a good amount extra on top too. However, the new structure means that instead of requests being the “unit of measure” of a Cursor plan, it’s now tokens. This means that there is now an incentive to be smarter about your own token usage.
To help keep your token usage low, please consider the following tips:
- Thinking Model Usage: Thinking models produce a lot of tokens. Its often very helpful to use thinking models in situations where non-thinking models aren’t getting the job done. However, there are thousands of requests done each day with thinking models that would be done just as well (and probably a few seconds quicker!) with the non-thinking equivalent.
- Conversation Length Compounding: As you chat to the LLM, your chat history grows in length - not just from the messages itself, but the thinking tokens, your rules, MCP servers, file contents and terminals. This means that, even in relatively average conversations, the token usage can be very high. The team are working on some more in-app feedback to help you manage this usage, but in the meantime, regularly restarting your chat thread can help to avoid sending thousands of useless tokens (old files, messages about old topics, etc) over and over again, which can cause the high cache read token usage
- Rules: Rules are a very powerful feature to make use of in Cursor, but to ensure the LLM sticks to them, they are included in every thread sent to the LLM (depending on the parameters you set for them). As such, every message will include a either a cache write or cache read for the token volume of your rules. Therefore, consider trying to make your rules concise and to the point, to avoid unnecessarily high token usage.
- Auto: In all paid plans, the
Automode is totally free and unlimited
As mentioned, the team are working hard to bring improved visibility on the token usage in-app to make it easier to navigate this in the future!
2 Likes
Didn’t answer a single question, just poured out meaningless fluff again.
“It’s not our fault, it’s you — you’re using the product wrong, that’s why it consumes 10 times more tokens.”
Please use the ‘Auto’ mode, which gives unlimited access to free models — our generous offer for just $20.
Bon appétit ![]()
10 Likes
exactly ![]()
It’s simple — they’re completely money-minded now. Since they’re not facing any serious competition at the moment, they’re leveraging their monopoly. All they want is to extract as much revenue as possible, which, while natural in business, isn’t ethical when it involves squeezing money from your top-tier user base.
1 Like