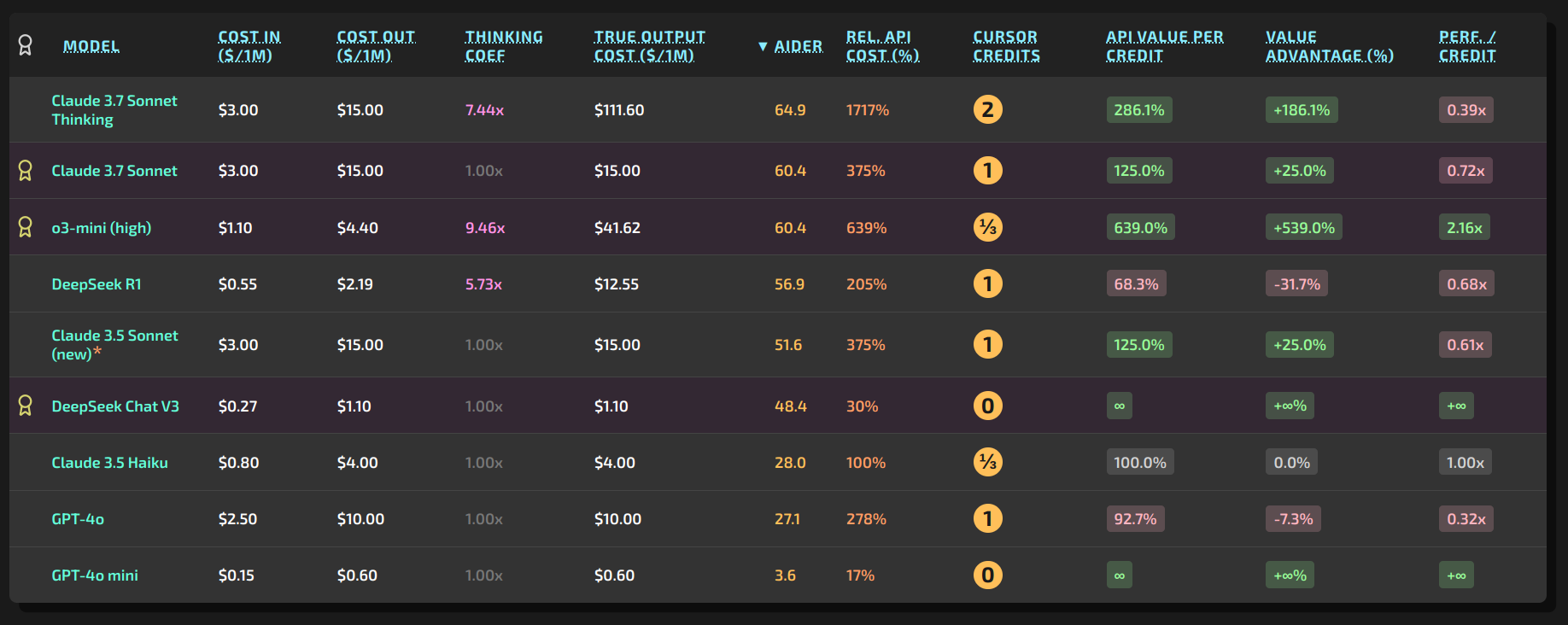
Hello, I have made a simple interactive table showing models available in Cursor. It was quite a nice learning experience with Alpine. I used many different models - V3 for small things, o3-mini-high for harder stuff, and sometimes Sonnet 3.7. Despite generally liking Sonnet a lot, for this particular project o3-mini was actually better at handling more difficult refactors, even compared to the thinking version of Sonnet.
Edit: That award ribbon is automatic - given to model with best Aider score in its credit group. It is not necessarily the best choice (eg I would personally wouldn’t recommend Sonnet 3.7 on Cursor because of the price of o3-mini-high which I view like a better go-to model; for those more credit saving I would recommend V3, then o3-mini-high, then Sonnet 3.7 and then thinking)
Those are best performance (in the Aider Polyglot bench) in credit group (among models which costs the same amount of credits in Cursor).
Not quite. For example V3 - it means, it is the best from models which cost 0 credits, here only other model with cost 0 is 4o mini. I tend to agree with Aider Polyglot bench more than other benches (eg coding in LMArena), that is why I used that one.
o3-mini-high is in my opinion currently the best value (quality) for price (third credit per use), even overall. Others with third credit price is Haiku and even though it can better use agentic tools, it is just a bit weaker model.
If you need best performance, then it looks like Sonnet 3.7 thinking is best current. But I am pretty sure I read on this forum they plan to make it to cost 3 times compared to non-thinking version. If that happens, then Sonnet 3.7 thinking would be overpriced in my opinion and much better choice would be Sonnet 3.7 non-thinking, since it would cost 3 times less and quality in benches is not three times worse, only like 5%. So best go-to model would be Sonnet 3.7 and only rarely would you try the thinking variant. Probably best would be to try o3-mini-high before the overpriced thinking sonnet.
It is the Aider bench (I think few different languages, not only Python like so many other benches, and I think tasks from exorscism, so between puzzles and real code, probably?). I have added much better explanations including links to mentioned benches.
Added it with the last update .
Unless something drastically changed in last day or two, yes.
In a similar, but slightly different context, I was wondering if certain models worked better/worse in various IDE’s? For example, does anyone have an opinion on the best models to use in Xcode with Swift?
I used Grok2 on my first two projects and it worked well. However, on my current project, I selected a series of models. Not knowing if this was a good idea or not, I thought I’d give it a try. Without any objective criteria, it’s hard to determine any particular/specific differences. As well, I experienced a lot of crashes yesterday. Although, many others did as well, so selected models likely were separate.
Anyway, I’d be interested in recommendations for the best models to use for specific development and IDE’s.
Another leaderboard that might be helpful: https://web.lmarena.ai/leaderboard (I have no idea how they managed to get such a high score for DeepSeek-R1. Maybe we should pay attention to projects that can effectively utilize DeepSeek-R1? I certainly can’t make good use of it.)
You can see the problems used by aider polyglot here: https://github.com/Aider-AI/polyglot-benchmark. I briefly looked at one problem, and it seemed similar to LeetCode-style algorithm questions. I didn’t look at many, so I’m not sure if it has problems related to real-world development.
Also, o3-mini-high achieved a high score, but I wouldn’t expect a model that, according to the official documentation, “Counts as 1/3 fast request” and has a “Pricing” of $0.01 to be “high” rather than “medium” or even “low”. You can see the discussion about this “low,” “medium,” and “high” versions here:
Yeah, LMArena is questionable, I view it as worthless hype-driven nonsense (overall and coding parts). I remember the times when Sonnet 3.5 (and 3.6) was for me the best, yet on the arena was best 4o or even some gemini pro. No, from my testing, they were always few levels under sonnet. Nowhere near the intuitive beast Sonnet was and still is. I believe on LMArena people are trying some toy questions, not even those more clever ones like from leetcode.
Though for front-end, that https://web.lmarena.ai/leaderboard seems to capture the quality better. I see o3-mini-high more recommended for back-end and planning, so I find it in a realm of possibility for R1 to be better.
Edit: R1 was pretty good from my testing, but yeah, not on par o3-mini-high nor sonnet 3.6 or 3.7. Had it been priced reasonably, according to API pricing, then it could be a useful middle model, bellow o3-mini-high, sonnet, maybe even 4o, but also cheaper.
Yeah, exorcism is similar to leetcode, but still better (different languages and I believe also different operations on code, not just writing from scratch) than supposedly general programming benchmarks done virtually only on Python, creating (unrealistically) well defined function or script and especially in majority on ML tasks, usually without types. And this is coming from a dev who likes Haskell and its brevity in well-defined functions, puzzles, golf code.
And I agree. It is very strange, but because of how the pricing of Cursor works, o3-mini-high is the best value to quality ratio. In normal world o3-mini-high would cost like 2/3 or 1, and R1 should cost like the 1/3 or 1/4. It doesn’t even make sense that o3-mini-high costs in credits same as Haiku which is much worse; or Sonnet costing same as 4o which is like in API by 1/3 cheaper, so should be 2/3 of a credit… I suspect Cursor team have some special contracts with OpenAI for the o3-mini-high and failed to find US served R1 for normal cost. Another thing I recently came across that there are some issues with context window in Cursor, some new restrictions and discussions about it are being censored (here and on reddit), so that could another reason for the weird credit pricing.
Different “AIs”, LLMs have different strengths across languages, paradigms, libraries, coding styles. In case of some AIs this can drastically change even in minor releases (eg GPT-4o is guilty of this many times, I think gemini too).
Then each platform (eg ChatGPT or ClaudeAI) or program (eg Aider or Goose) or IDE (Cursor, that censored here from Cod eium, Trae) or AI plugin (Copilot, Continue.dev) have their own way of working with an AI - from system/pre- prompt to RAG or agentic tools. This can quickly change in minor release or even no release (eg in case of Cursor when they change backend code).
You have so many moving parts which are hard to test automatically. Most likely in a time when you would finish manual testing even few most used languages (3? 5?), most used libraries/frameworks for all these (10? more?) and IDEs/plugins/programs (6? 8?) at least one major change would already occur and you could go back to retesting it…
Edit: I also forgot about an interesting phenomena - many models are much better at modifying/extending code they wrote, and much worse doing this to human code or code from other AI, even their own lineage - eg Sonnet 3.7 had difficult time refactoring and expanding code from Sonnet 3.6, but one shot complete solution with the required new features.
Edit2: Remembered this bench - ProLLM Benchmarks it allows filtering by language and has Swift. Too bad it looks like for Swift the bench is saturated, so not really apparent what is better .
I am not sure it is worth following, there are most likely better ways (like grabbing an existing table component).
I started on Perplexity (Sonnet 3.7) with search for API prices of the models, then in same thread I gave it copied table from Aider bench results and Cursor models (from Cursor wiki). Then with AIlin (adds HTML preview) I iterated over it on Perplexity (most of the color theme and design comes from Sonnet, I gave it only something vague like “dark theme, clean”), still a static table. Then I thought it could be nice to add some metrics (credits vs API price, credits vs bench score), sorting and since I recently saw AlpineJS (I am mostly used to React), a minimal front-end library, I though I could use that, see and learn from how Sonnet uses it.
I think at this point it got a bit too big for Perplexity to handle (response limit is like 3.5k tokens, couple hundred lines), so I moved to Cursor (for live preview I used Live Server extension). There with each feature or fix I would first try V3, few forth and back (just in chat mode, since it is a single file application), if not solved (surprisingly fairly rare, like only 20%) tried o3-mini (or Sonnet 3.7), if still no luck I would try last resort (Sonnet 3.7 if previous was o3-mini, or the other way around). I only had to manually touch the code few times, mostly minor visual tweaks (after all Alpine was rather unknown to me). AI, even those medium sized ones like o3-mini or V3 can explain basics of better known languages/frameworks/libraries pretty well (I would use R1, but the credit cost is too high - 1 credit, especially compared to o3-mini at 1/3 credit while o3-mini usually giving better responses).
Released an update - added Gemini 2.5 Pro and Grok 2 (sadly no Aider bench results). Some smaller fixes like icons from different more reliable CDN, copy for inline codeblocks, added agent column.
That new Gemini looks really good on paper. Tried it few times and seemed to be working okay, though sometimes a bit weird long pauses. But code was quite solid.
Gemini 2.5 Pro might be the winner, even if they would increase price to 2x, still better than Sonnet 3.7 thinking. And for Sonnet 3.7 non-thinking is better to pick o3-mini - costs third of what Sonnet and has similar capabilities.
Unfortunately R1 is still severly overpriced: $0.55 in, $2.19 out, yet costs 1 credit. Nobody sane would use it when o3-mini ($1.10 in, $4.40 out) costs 1/3 credit and Gemini 2.5 Pro ($1.25 in, $10.00 out) costs 1 credit, both much higher in benches.
If it is because privacy and security, then why not give users a choice - add a checkbox to use Chinese servers and pay 1/3 credit instead of fat US price. I don’t care if they steal my open-source or toy project code…
As long as o4-mini is free, I would recommend using that. What after it isn’t free will depend on the new price. If 1/3 then it would be best in that category. If 1 then Gemini 2.5 Pro is better pick (same price, on average more capable).
At 0 credits category, GPT-4.1 and Grok 3 Mini look better than older DeepSeek V3. But GPT-4.1 probably won’t stay free. Grok 3 Mini might, it could a minor bump until they add V3.1 (V3 0324).
Thanks for making these charts. I agree 4.1 probably won’t stay free. Do you think they might have it cost half a credit, or will it be a full credit like GPT-4o? (I’m really enjoying it free right now.)
GPT-4.1 and o4-mini are going to be full 1 use/credit… Neither choice feels correct to me. 4.1 is not bad (feels pretty snappy), but nowhere near Gemini 2.5 Pro or Sonnet 3.7 which all cost 1 credit. o4-mini high is pretty capable, but pricing it now at 1 credit, when o4-mini costs exactly the same in API as o3-mini, which costs third of a credit/use is … rather terrible. Cost update for GPT-4.1 and o4-mini
I am working on updating the table.
I kinda liked both models (though o4-mini today was so slow, like 5 minutes to change 3 lines…). But neither is worth 1 credit in my opinion.