Cursor team is censoring stuff now woah, make the tool bad and not allow saying so
1 Like
Dude, it’s not a bug. The Cursor team has mentioned this on the message boards already. You just don’t know how to use agent mode, which is 99.9% fully automatic.
1 Like
Can you share the post they explain why it takes this much token to make tiny edit, and is their how-to-use-agents guide published?
Yes you must consult with the magic orb ![]() before every prompt. Takes years of practice to do so effectively.
before every prompt. Takes years of practice to do so effectively.
recent update from the cursor team on the token consumption:
There were 3 tool calls and equivalent token usage to 24 reads soooo
As Enterprise-tier user, I have not this unfortunate problem. Potential hints :
- Are background agents running ? It will skyrocket your agent usage
- Auto is designed at best to make you use the model cursor wants you to use. My first idea was basically to load-balance models usage and by using auto you’d end up using bad models by design.
I admit I never envisioned they could actually do the opposite and make people models’ usage skyrocket by making them use likely max models that burn up 200 seat per request on my enterprise tier…
Cursor must address this quickly by giving clear answers, at this point to apologize without addressing the issue is pointless and hurting cursors’ brand.
Dude, it’s literally a bug: Unofficial Community Discussion to Give Fedback on Plan Rates - #7 by mokhir
92% of total usage is Cache Read. I start a new chat for everything, i only have 1 MCP server which is rarely used, this ain’t normal.
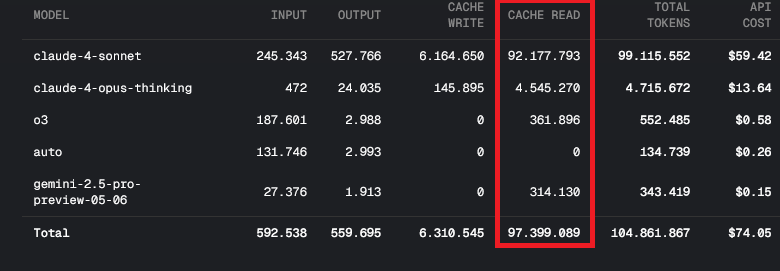
I have the same bug but according to Cursor staff it’s not a bug, it’s a skill issue on our end.
![]() how even this happened?
how even this happened?
Just directly asked the AI in my chat “what model are you?” and it explicitly responded that it’s Claude 3.5 Sonnet - despite having Claude 4 selected in my settings. This confirms they are charging premium Claude 4 rates while delivering Claude 3.5 responses. This cannot be a coincidence or technical glitch - it appears to be systematic misrepresentation of services and charging user way too much.

Looks like their is other ai decides model before forward request
I looked back through my May and June usage. NIGHT AND DAY DIFFERENCE IN TOKEN USAGE. I know they changed how it is accounted but even same time sums of older requests are so much less token usage than what is current now. I do not know how the team ignores this. We are all STEM folks here. There has to have been an impulse for this. I have gotten better at prompting if anything, not worse lol.
1 Like
@devv This has been debunked several times and your post proves its a hallucination.
You used Claude 4 Sonnet Thinking:
- It has a thinking ability.
- It shows “Thought for 6s”
Claude 3.5 Sonnet
- Has no thinking ability
- Can not show thinking blocks
- Therefore its a clear hallucination.
We do not route any models to other models except Auto. This has been confirmed several times already by various Cursor team members.
The “Thought for 6s” shows that it can not be a wronly routed model as 3.5 does not have thinking.
Please be careful with accusations and insinuations where you are clearly in the wrong!
@Mohamed_Khafagy only the Auto model routes to other models. Any non-Auto model is accessed directly as labeled.
The ‘thinking’ capability can be simulated at the UI level while different models handle the actual processing. Modern software architectures use proxy layers, caching systems, and hybrid approaches that can absolutely create this exact scenario. The fact that I’m getting explicit responses stating ‘I am Claude 3.5 Sonnet’ when asked directly about model identity is not a hallucination - it’s a technical indicator of what model is actually generating the response.
If Cursor’s architecture is as straightforward as claimed, they should be able to provide technical logs showing the exact API calls being made to Anthropic. I can provide the exact timestamps of my interactions - can you show the corresponding API logs proving Claude 4 was actually called during those specific times?
More concerning is the tone of this response. A company with a $9.9 billion valuation allowing their representatives to speak to paying customers with condescending language like ‘you are clearly in the wrong’ and dismissing legitimate technical concerns speaks volumes about the culture and practices happening under the hood. Professional companies address billing discrepancies with technical evidence, not defensive hostility.
When customers raise billing concerns backed by direct model responses, the appropriate response is investigation and transparency - not aggressive dismissal. This tone suggests a company more interested in protecting their narrative than resolving customer issues, which aligns perfectly with the pattern of billing problems and user exodus we’re seeing across social media.
1 Like
Sorry I don’t have access to users requests, so I cant prove what you see. The issue has been posted several times and its sure concerning seeing a wrong output, I understand that.
Several devs have confirmed this in the forum, it is not a case of wrongly routing of requests.
Hold on! you just told me I’m ‘clearly in the wrong’ and made all these definitive statements about how your system works, but now you’re saying you don’t actually have access to see what happened on my account?
That doesn’t make sense. How can you be so certain I’m wrong about something you can’t even look at?
Look, I’m not trying to attack anyone here. I’m a paying customer who noticed my AI is telling me it’s Claude 3.5 when I have Claude 4 selected. That’s a legitimate concern, right? But what’s really worrying me is the money aspect - I’ve been charged premium rates for Claude 4, and if I’m actually getting 3.5 responses, that’s a billing issue that affects not just me but potentially other developers too.
When I raised this concern, I got told I’m ‘clearly wrong’ by someone who then admits they can’t actually check what happened. That’s concerning when we’re talking about people’s money.
I get that you’ve probably seen similar posts before, but dismissing customers without being able to verify what they’re experiencing isn’t great customer service, especially when it involves billing discrepancies. If your devs have looked into this and ruled out routing issues, that’s fine - but can you point me to where they explained how they verified that? Because from where I’m sitting, I’m seeing one thing and being told something completely different.
I just want to understand what’s happening with my account and whether other developers are facing the same billing concerns. The defensive response makes it feel like there’s something to hide!
1 Like
Your concern is valid and thats why I did separate checks many times over last few weeks every time someone posts such screenshots and makes the same claims. The clear proof is in the screenshot.
In about 30% of cases even on Anthropic console I got the same issue in the past cases where I posted it with proof in forum.
For me thats sufficient proof. Why?
- Each model is named ‘Claude’
- Claude 4 models were trained with content that had knowledge of Claude 3.5 Sonnet.
- The model tries to be helpful and do its best to provide information.
- All models provide a helpful sounding output when they do not have sufficient info, humans call this “hallucination” although its just a probability based response. In this case the model knows Claude 3.5 Sonnet.
As Cursor devs have stated so repeatedly the models route to what you see in the UI. They have tested it also.
I really understand your concern but you claimed “This cannot be a coincidence or technical glitch - it appears to be systematic misrepresentation of services and charging user way too much.” and I corrected you on that.
There is no systematic misrepresentation or technical glitch and I think its highly inappropriate to make such false claims in the forum.
If you provide a Request ID I can ask the dev team to check your specific request. You could have asked us to do so.
What the Anthropic API receives is an Claude 4 Sonnet Thinking request if you requested that model.
(Side note, you may find it externally and I wont go into that in detail as its not our issue, last week Opus 4 claimed the same on Anthropic directly)